快速卷积网络如何实现
使用numpy实现了一个简单的卷积网络,但是训练速度比tensorflow慢10倍左右,请问还有哪里可以优化的吗
import numpy as np
import tensorflow as tf
import time
"""
将输入按卷积核拆分为N个卷积核大小的张量
Parameters
----------
A: 输入数据,形状为(样本数,宽,高,通道)
dim:当前卷积层的维度信息
Return
------
(输出宽 * 输出高, 样本数, 核宽 * 核高, 输入通道数)
"""
def split(A, dim):
res = []
num_datas = A.shape[0]
width_A = A.shape[1]
height_A = A.shape[2]
channel_A = A.shape[3]
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
stride_w = dim['strides'][0]
stride_h = dim['strides'][1]
for k in range(0, width_A - width_kernel + 1, stride_w):
for j in range(0, height_A-height_kernel+1, stride_h):
res.append(A[:, k:k+width_kernel, j:j+height_kernel, :].reshape(num_datas, width_kernel*height_kernel, channel_A))
return np.array(res)
def split_pool(A, dim):
res = []
width_A = A.shape[1]
height_A = A.shape[2]
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
stride_w = dim['strides'][0]
stride_h = dim['strides'][1]
for k in range(0, width_A - width_kernel + 1, stride_w):
for j in range(0, height_A-height_kernel+1, stride_h):
slice = A[:, k:k + width_kernel, j:j + height_kernel, :]
mask = (slice == np.max(slice, axis=(1, 2))[:, np.newaxis, np.newaxis, :])
res.append(mask)
return np.array(res)
def relu(Z):
return np.maximum(0, Z)
def softmax(X):
X_exp = np.exp(X)
return X_exp / np.sum(X_exp, axis=0)
def loss_cross_entropy(Y_pre, Y_label):
return -np.sum(Y_label * np.nan_to_num(np.log(Y_pre), nan=0))/Y_pre.shape[1]
class Conv2d:
"""
Parameters
----------
dims: type(0:输入,1:卷积, 2:池化, 3: 全连接) kernel(卷积核) strides(步长)
"""
def __init__(self, dims):
self.dims = dims
self.rng = np.random.default_rng(seed=2)
self.outs = []
self.lrate = .1
for i in range(len(dims) - 1):
dim = dims[i + 1]
dim_bef = dims[i]
if dim['type'] == 1:
width_bef = dim_bef['size_out'][0]
height_bef = dim_bef['size_out'][1]
channel_bef = dim_bef['size_out'][2]
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
channel_out = dim['kernel'][2]
width_out = width_bef - width_kernel + 1
height_out = height_bef - height_kernel + 1
dim['size_out'] = (width_out, height_out, channel_out)
dim['weight'] = tf.keras.initializers.RandomNormal(0, .03, seed=2)(shape=(width_kernel, height_kernel, channel_bef, channel_out)).numpy()
# dim['weight'] = self.rng.normal(0, .03, (width_kernel, height_kernel, channel_bef, channel_out))
dim['bias'] = np.zeros(channel_out)
if dim['type'] == 2:
width_bef = dim_bef['size_out'][0]
height_bef = dim_bef['size_out'][1]
channel_bef = dim_bef['size_out'][2]
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
width_out = int((width_bef - width_kernel)/width_kernel) + 1
height_out = int((height_bef - height_kernel)/height_kernel) + 1
dim['size_out'] = (width_out, height_out, channel_bef)
if dim['type'] == 3:
size_out = dim['size_out']
if dim_bef['type'] != 3:
width_bef = dim_bef['size_out'][0]
height_bef = dim_bef['size_out'][1]
channel_bef = dim_bef['size_out'][2]
size_in = width_bef * height_bef * channel_bef
else:
size_in = dim_bef['size_out']
dim['weight'] = tf.keras.initializers.RandomNormal(0, .03, seed=2)(shape=(size_in, size_out)).numpy().T
#dim['weight'] = self.rng.normal(0, .03, (size_out, size_in))
dim['bias'] = np.zeros(shape=(size_out, 1))
def forward(self, X, Y):
start_time = time.time()*1000
cost_split = 0
self.outs = [(X, X)]
A = X
for i in range(len(self.dims) - 1):
dim = self.dims[i + 1]
dim_bef = self.dims[i]
type = dim['type']
num_datas = A.shape[0]
if type == 1:
weight = dim['weight']
bias = dim['bias']
width_out = dim['size_out'][0]
height_out = dim['size_out'][1]
channel_out = dim['size_out'][2]
#(输出宽 * 输出高, 样本数, 核宽 * 核高, 输入通道数)
start_split = time.time() * 1000
A_split = split(A, dim)
cost_split += time.time() * 1000 - start_split
A_split = A_split.reshape(-1, A_split.shape[-2] * A_split.shape[-1])
#(核宽*核高*输入通道,输出通道)
W = weight.reshape(-1, weight.shape[-1])
#(输出宽*输出高*样本数,输出通道)
Z = A_split.dot(W).reshape(width_out, height_out, num_datas, channel_out).transpose(2, 0, 1, 3) + bias
A = relu(Z)
if type == 2:
width_out = dim['size_out'][0]
height_out = dim['size_out'][1]
channel_out = dim['size_out'][2]
start_split = time.time() * 1000
#(输出宽 * 输出高, 样本数, 核宽 * 核高, 输入通道数)
A_split = split(A, dim)
cost_split += time.time() * 1000 - start_split
A = np.max(A_split, axis=2).reshape(width_out, height_out, num_datas, channel_out).transpose(2, 0, 1, 3)
if type == 3:
weight = dim['weight']
bias = dim['bias']
if dim_bef['type'] != 3:
A = A.reshape(A.shape[0], A.shape[1] * A.shape[2] * A.shape[3]).T
Z = weight.dot(A) + bias
if i == len(self.dims) - 2:
A = softmax(Z)
else:
A = relu(Z)
self.outs.append((Z, A))
loss = loss_cross_entropy(A, Y)
end_time = time.time() * 1000
cost_time = end_time - start_time
return A, loss, int(cost_time), int(cost_split)
def backward(self, Y):
start_time = time.time() * 1000
num_datas = Y.shape[1]
Z, A = self.outs[-1]
dZ = (A - Y)/Y.shape[1]
for i in range(len(self.dims) - 1):
dim = self.dims[-1-i]
dim_bef = self.dims[-2-i]
Z_bef, A_bef = self.outs[-2 - i]
Z, A = self.outs[-1-i]
if dim['type'] == 3:
if i > 0:
dZ = dA * (Z > 0)
if A_bef.ndim != 2:
A_bef = A_bef.reshape(A_bef.shape[0], -1).T
dW = dZ.dot(A_bef.T)
dB = np.sum(dZ, axis=1)[..., np.newaxis]
dA = dim['weight'].T.dot(dZ)
dim['weight'] -= self.lrate * dW
dim['bias'] -= self.lrate * dB
if dim['type'] == 1:
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
width_out = dim['size_out'][0]
height_out = dim['size_out'][1]
channel_out = dim['size_out'][2]
width_in = dim_bef['size_out'][0]
height_in = dim_bef['size_out'][1]
channel_in = dim_bef['size_out'][2]
weight = dim['weight'];
if dA.ndim == 2:
dA = dA.T.reshape(num_datas, width_out, height_out, channel_out)
dZ = dA * (Z > 0)
dB = np.sum(dZ, axis=(0, 1, 2))
#(输出宽 * 输出高, 样本数, 核宽 * 核高, 输入通道数)
A_split = split(A_bef, dim)
#(核宽*核高*输入通道数,输出宽*输出高*样本数)
A_split = A_split.reshape(-1, A_split.shape[-2] * A_split.shape[-1]).T
#(输出宽*输出高*样本数,输出通道数)
dZ_flatten = dZ.transpose(1, 2, 0, 3).reshape(-1, dZ.shape[-1])
#(核宽*核高*输入通道数,输出通道数)
dW = A_split.dot(dZ_flatten).reshape(width_kernel, height_kernel, channel_in, channel_out)
width_pad = width_kernel - 1
height_pad = height_kernel - 1
dZ_pad = np.pad(dZ, ((0, 0), (width_pad,width_pad), (height_pad,height_pad), (0,0)), mode='constant')
#(核宽 * 核高 * 输出通道数,输入通道数)
weight_rot = np.rot90(weight, k=2).transpose(0, 1, 3, 2).reshape(-1, weight.shape[2])
#(输入宽 * 输入高, 样本数, 核宽 * 核高, 输出通道数)
dZ_split = split(dZ_pad, dim)
dZ_split = dZ_split.reshape(-1, dZ_split.shape[-2] * dZ_split.shape[-1])
# (输入宽 * 输入高 * 样本数, 输入通道数)
dA = dZ_split.dot(weight_rot).reshape(width_in, height_in, num_datas, channel_in).transpose(2, 0, 1, 3)
dim['weight'] -= self.lrate * dW
dim['bias'] -= self.lrate * dB
if dim['type'] == 2:
width_out = dim['size_out'][0]
height_out = dim['size_out'][1]
channel_out = dim['size_out'][2]
width_kernel = dim['kernel'][0]
height_kernel = dim['kernel'][1]
width_in = dim_bef['size_out'][0]
height_in = dim_bef['size_out'][1]
channel_in = dim_bef['size_out'][2]
dZ = dA
if dZ.ndim == 2:
dZ = dZ.T.reshape(num_datas, width_out, height_out, channel_out)
#(输出宽 * 输出高, 样本数, 核宽, 核高, 输入通道数)
A_split = split_pool(A_bef, dim)
# (样本数, 输出宽, 输出高, 核宽, 核高, 输入通道数)
A_split = A_split.transpose(1, 0, 2, 3, 4).reshape(num_datas, width_out, height_out, width_kernel, height_kernel, channel_in)
dA = A_split * dZ[:, :, :, np.newaxis, np.newaxis, :]
dA = dA.transpose(0, 1, 3, 2, 4, 5).reshape(num_datas, width_out*width_kernel, height_out*height_kernel, channel_in)
width_pad = width_in - width_out*width_kernel
height_pad = height_in - height_out*height_kernel
dA = np.pad(dA, ((0, 0), (0, width_pad), (0, height_pad), (0, 0)), mode='constant')
end_time = time.time() * 1000
cost_time = end_time - start_time
return int(cost_time)
tf会利用cpu的avx指令集,多核并行以及显卡加速,而 numpy 自己实现显然利用不了这些,慢那是自然的了。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/710267
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Python TensorFlow,张量,张量的形状、类型、阶
- 除此之外, 这篇博客: 使用TensorFlow编程实现一元逻辑回归中的 交差熵损失函数: 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
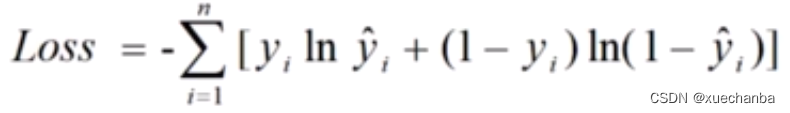
非常感谢提供代码,以下是代码的优化建议:
使用numpy的向量化运算函数,可以避免循环,从而加速代码。例如,dot函数可以用于矩阵乘法,conv2d函数可以用于卷积操作。
将计算图形编译为静态图形,这将使计算更快。TensorFlow在编译后使用C++进行计算,这比Python更快。
避免过多的内存分配。预先分配数组,并重复使用它们,以减少内存分配次数。如果必须动态分配内存,则可以考虑使用numpy.resize而不是append方法。
编写高效的代码。应该尽量避免使用Python列表和for循环等缓慢的操作。相反,应该使用numpy的数组、切片、广播和向量化操作等功能。
以下是部分代码的优化示例:
- 优化loss_cross_entropy函数
原函数中使用了np.sum()方法,因为该方法会返回一个标量,所以需要将其转换为一个浮点数。但是,在转换过程中会出现一些开销,导致训练速度较慢。我们可以简单地将np.sum()替换为np.dot()来加速计算:
def loss_cross_entropy(Y_pre, Y_label):
m = Y_pre.shape[1] # 样本数量
logprobs = np.dot(Y_label, np.log(Y_pre).T)
loss = -1/m * np.sum(logprobs)
return loss
- 优化卷积操作
可以使用numpy的convolve函数代替两个for循环来实现卷积操作:
def conv_single_step(a_slice_prev, W, b):
s = np.multiply(a_slice_prev, W) + b
Z = np.sum(s)
return Z
def conv_forward(A_prev, W, b, hparameters):
stride = hparameters['stride']
pad = hparameters['pad']
# Pad the previous activation
A_prev_pad = np.pad(A_prev, ((0,0), (pad,pad), (pad,pad), (0,0)), 'constant', constant_values=(0,))
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev_pad.shape
(f, f, n_C_prev, n_C) = W.shape
n_H = int((n_H_prev - f) / stride) + 1
n_W = int((n_W_prev - f) / stride) + 1
Z = np.zeros((m, n_H, n_W, n_C))
for i in range(m):
a_prev_pad = A_prev_pad[i,:,:,:]
for h in range(n_H):
vert_start = h * stride
vert_end = vert_start + f
for w in range(n_W):
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C):
a_slice_prev = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
weights = W[:, :, :, c]
biases = b[:, :, :, c]
Z[i, h, w, c] = conv_single_step(a_slice_prev, weights, biases)
return Z
- 优化池化操作
同样可以使用numpy的向量化运算来代替for循环。例如,使用numpy的kron函数可以实现最大池化操作:
def create_mask_from_window(x):
mask = x == np.max(x)
return mask
def pool_forward(A_prev, hparameters, mode="max"):
stride = hparameters['stride']
f = hparameters['f']
m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape
n_H = int((n_H_prev - f) / stride) + 1
n_W = int((n_W_prev - f) / stride) + 1
n_C = n_C_prev
A = np.zeros((m, n_H, n_W, n_C))
for i in range(m):
for h in range(n_H):
vert_start = h * stride
vert_end = vert_start + f
for w in range(n_W):
horiz_start = w * stride
horiz_end = horiz_start + f
for c in range(n_C):
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
if mode == "max":
mask = create_mask_from_window(a_prev_slice)
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":
A[i, h, w, c] = np.mean(a_prev_slice)
cache = (A_prev, hparameters)
return A, cache