python调用sklearn
求问python代码意义,是怎么求precision、recall和f1值的?
precision_val = sklearn.metrics.precision_score(target_inds.squeeze().flatten(), y_hat.flatten(), average='weighted')
recall_val = sklearn.metrics.recall_score(target_inds.squeeze().flatten(), y_hat.flatten(), average='weighted')
f1_val = sklearn.metrics.f1_score(target_inds.squeeze().flatten(), y_hat.flatten(), average='weighted')
这段代码中,使用了sklearn库中的metrics模块来计算分类模型的precision(精确率)、recall(召回率)和f1值(F1分数)。
- precision_score()函数用于计算精确率,即模型预测为正例的样本中实际为正例的比例。
- recall_score()函数用于计算召回率,即模型正确预测为正例的样本占实际为正例样本的比例。
- f1_score()函数用于计算F1分数,即精确率和召回率的调和平均值,可以综合评估模型的性能。
这里的参数含义:
- target_inds.squeeze().flatten():真实标签数据,将其从多维数组转为一维数组。
- y_hat.flatten():模型的预测结果,将其从多维数组转为一维数组。
- average='weighted':对于多类别分类问题,使用加权平均值计算精确率、召回率和F1值,权重为每个类别的样本数。也可以选择其他的参数值,如'binary'(二分类问题)、'macro'(对所有类别求平均值)和'micro'(将所有类别看作一个整体计算指标值)。
- 请看👉 :机器学习—神经网络算法—调sklearn库实现(Accuracy、Precision、Recall、F1-score)
- 除此之外, 这篇博客: 机器学习之分类模型评估指标及sklearn代码实现中的 Recall(召回率) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
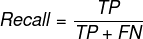
用阳性来举例
简单来说就是用于评判模型能不能很好的找出阳性样本,即 阳性样本中被模型识别出阳性的数量/实际的阳性样本数量,这里阳性的recall = 3 / 3 = 100%
说明模型recall非常好,因为乳腺癌是宁可错杀也不可放过的,因此需要有较高的召回率才行的,对阳性样本需要有较高的识别度。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^