openpyxl库无法全部写入文本到单元格
关于使用openpyxl库,在单个单元格内无法完全将字符串插入的问题。
# 新建Excel文件,如果文件已经存在,则打开该文件
filename = "examplwe.xlsx"
print(filename)
if os.path.exists(filename):
wb = openpyxl.load_workbook(filename)
else:
wb = openpyxl.Workbook()
# 选择第一个工作表
worksheet = wb.active
#获取链接
hrefs = get_href_list(url)
wenben = urltaitou + hrefs[0]
all_text_str = get_all_text(wenben)
print(wenben,all_text_str)
worksheet.cell(1, 1, all_text_str)
# 保存文件
wb.save(filename)
代码如上,我要爬取某个网站的全部文本信息,由于网页文本较多,all_text_str字符串大概有15000个汉字,且由于某种原因,这些文本只能放置在一个单元格内(execl单元格完全可以放下那么多汉字),但是每次单元格内只能插入不到2000字,有时多有时少。
我在网上查了很久,没有相关信息。
我自己排查了很久,不知道问题出在哪里。
1、已排查获取的文本是否有特殊格式:没有特殊格式,全为汉字
2、是否是openpyxl库的问题:目前看来并不是,因为我也尝试了pandas 库,问题依旧
3、其他网页的文本是否可以全部置入单元格内:没有尝试过,但是应该不是,因为我尝试给字符串赋值全汉字,但是也无法全部放置进去
如上,请各位不吝赐教。谢谢了!
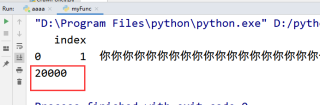
关于python写入汉字到Excel无法全部写入的问题,我认为是你的文本中有空格或者其它字符的问题,我用python的pandas库测试过,可以在一个单元格内存入2万个汉字。测试代码:
import pandas as pd
text = '你'
text = text*20000
data = pd.DataFrame([[1,text]],columns=['index','name'])
data.to_excel('text.xlsx',encoding='utf8')
d = pd.read_excel('text.xlsx',encoding='utf8',index_col=0)
print(len(d.iloc[0]['name']))
从最后的结果可以看到,我往一个单元格内存入了2万个‘你’ 最后再读取出来,文本的长度依然是2万。所有是可以存储这个多文本的,应该是文本中还有其他格式的数据。
该答案引用ChatGPT的部分内容:
您可以使用Python的win32com库来调用Excel VBA的方法来实现在单个单元格中写入超长字符串的操作。以下是一个示例代码:
import win32com.client
# 创建Excel对象
excel = win32com.client.Dispatch("Excel.Application")
# 打开文件
wb = excel.Workbooks.Open("example.xlsx")
worksheet = wb.ActiveSheet
# 获取需要写入的文本
myText = "This is a very long text string that needs to be written to a single cell in an Excel worksheet. The string is too long to fit in a single cell, so we need to use VBA to write it to the worksheet."
# 选择单元格
cell = worksheet.Range("A1")
# 将文本分割为小块,并逐块写入单元格
for i in range(0, len(myText), 32767):
cell.Value = myText[i:i+32767]
cell = cell.Offset(0, 1)
# 保存文件
wb.Save()
wb.Close()
# 关闭Excel对象
excel.Quit()
该示例代码使用win32com库调用Excel VBA的方法来实现将文本分割为小块,并逐块写入单元格的操作。请注意,使用该库需要您的机器安装了Microsoft Excel软件。
以下内容部分参考ChatGPT模型:
首先,建议将代码中的 worksheet.cell(1, 1, all_text_str) 改为 worksheet['A1'] = all_text_str,这样可以直接将字符串赋值给单元格。然后,可以通过以下代码将字符串分割成多个部分,分别赋值给多个单元格:
# 将字符串按每2000个字符分割成多个部分
text_parts = [all_text_str[i:i+2000] for i in range(0, len(all_text_str), 2000)]
# 将每个部分分别赋值给不同的单元格
for i, part in enumerate(text_parts):
worksheet.cell(1+i, 1, part)
这样可以将字符串分成多个部分,分别赋值到不同的单元格内,避免单个单元格无法完全存储字符串的问题。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7468711
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^该回答引用ChatGPT
根据你提供的代码和问题描述,我猜测你遇到的问题可能是单元格的长度限制。Excel单元格的默认长度是255个字符,如果超出了这个限制,有些字符就会被截断。你在单元格中插入的字符串可能正好超过了255个字符,因此只显示了一部分。
为了解决这个问题,你可以尝试设置单元格的列宽,以便它可以容纳更多的字符。以下是一个例子:
worksheet.column_dimensions['A'].width = 100
worksheet.cell(1, 1, all_text_str)
这将设置'A'列的宽度为100个字符,该列中的单元格应该可以容纳更多的字符。你可以根据你需要插入的字符数来调整列宽的大小。
另外,为了排除其他可能的问题,你可以检查一下字符串中是否存在特殊字符或控制符。这些字符可能会导致Excel无法正确地处理字符串。你可以尝试使用正则表达式或其他工具来移除这些字符。
希望这些建议能够帮助你解决问题。