关于#pythonscrapy#的问题,如何解决?
请问大家我在爬取一个叫Steinmart.com的网站,大家能帮我加一下注释吗?(越详细越好)以下是我的代码
import copy
import logging
import time
import json
import openpyxl
from scrapy import cmdline
from steinmart_com.items import SteinmartComItem
from scrapy.http.response.html import HtmlResponse
from steinmart_com.settings import ONLINE
import scrapy
import re
logging.basicConfig(filename=r'G:\spider_demo\spider\demo\steinmart_com\Steinmart.log', level=logging.INFO,
format='%(asctime)s %(message)s', filemode='w')
class Steinmart(scrapy.Spider):
name='Steinmart'
allowed_domains=['steinmart.com']
start_urls=['https://steinmart.com/']
index_url='https://steinmart.com/'
def start_requests(self):
if ONLINE:
wb=openpyxl.load_workbook('/home/yang/steinmart_com/steinmart_com/steinmart_com.xlsx')
else:
wb = openpyxl.load_workbook(r'G:\spider_demo\spider_demo\steinmart_com\steinmart_com\steinmart_com.xlsx')
ws=wb.active
for r in range(2,ws.max_row+1):
url=ws.cell(r,1).value
if not url:
continue
one, two, three, four=ws.cell(r,2).value, ws.cell(r,3).value, ws.cell(r,4).value, ws.cell(r,5).value
meta = {'url': url, 'category': one if one else'', 'sub_category': two if two else'',
'third_category': three if three else '','subdivision_cat':four if four else ''}
yield scrapy.Request(url, callback=self.parse, dont_filter = True, meta = meta)
def parse(self, response: HtmlResponse, ** kwangs):
meta=response.meta
sale_num=response.xpath('//*[eclass="collection-count"]/textO').get()
sale_num1=sale_num.strip()
sale_num2=sale_num1[:-5]
page_num=int(sale_num2)//20
if page_num:
for i in range(1, int(page_num)+1):
new_url=str(response.url)+'?page='+str(i)
yield scrapy.Request(new_url, callback=self.parse_list, dont_filter=True, meta=meta)
def parse_list(self, response: HtmlResponse):
meta = response.meta
product_list=response.xpath("//*[@class='col-lg-3 col-md-4 col-Sm-6']")
for product in product_list:
if not product.xpath("./a/div/div"):
continue
meta['brand_name']=product.xpath("./a/div[2]/div[1]/textO").get()
meta['url'] = self.index.url+product.xpath("./a/@href").get()
meta['title']=product.xpath("./a/div[2]/div[1]/textO").get()
meta['product_small_image'] = product.xpath("./a/div/div/img/@data-src").get()
yield scrapy.Request(meta['url'], callback=self.parse_detail, dont_filter = True, meta = meta)
def parse_detail(self, response: HtmlResponse):
meta = response.meta
item = SteinmartcomItem()
item['url'] = meta['url']
item['title'] = meta['title']
item['price_now'] = str(response.xpath('//*[@class="container"]/div[2]/div[2]/div[2]/div/textO)').get()).replace('$', '').replace('\t', '').replace('\n', '').strip()
print(item['title'])
print(item['price_now'])
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/756606
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:【Python 基础教程】错误与异常的处理
- 除此之外, 这篇博客: 利用python的交叉表功能展现用户调研结果中的 利用Python生成交叉表 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
以下是一个简单的样本数据,每一列都代表一个问题(维度)。

① 简单的二联表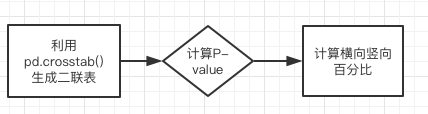
② 稍复杂的三联表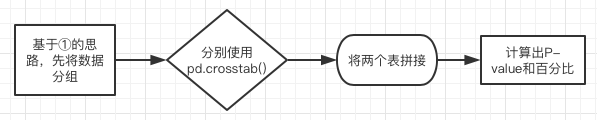
1. 获得原始数据import pandas as pd from scipy.stats import chi2_contingency from scipy.stats import chi2 import numpy as np import warnings warnings.filterwarnings("ignore")# General Purpose Crosstab Generator (GPCG) def dataRead(File): global data,data1,data2 #将变量设为全局变量 data = pd.read_excel(File) # data = data[data.gender == 'Female'] data1 = data[data.engager == "No"] data2 = data[data.engager == "Yes"] global y global z y = data['recall'] z = data['engager'] dataRead("Survey.xlsx")2. 交叉表的生成 -- ① 简单二联表
根据以上的示例图,我们将年龄表格左侧的第一个维度,是否记得营销广告作为分组的第二个维度。## ① ## ## 建立一个简单的交叉表,且横向维度只有Yes和No def type1(question,fix,Index): a = pd.crosstab(question, fix, margins=True) a['Non'] = a['No'] a['Yep'] = a['Yes'] a = a.drop('No',axis=1) a = a.drop('Yes',axis=1) a = a.drop('All', axis = 1) a = a.fillna(0) a = a.reindex(Index) #按照想要的方式排序 a.to_clipboard(excel=True) return a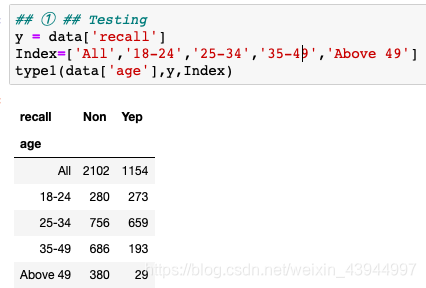
## ② ## ## 在简单的交叉表下方添加假设检验的结果 def p_val(val): if val < 0.05: return "<0.05" elif val < 0.1: return "<0.1" elif val < 0.15: return "<0.15" else: return ">0.15" def chsq_test(question,c,Index): chsq_rlt=[] C=type1(question,c,Index) C1=C.iloc[1:,[0,1]] # remove all zeroes try: C1=C1[(C1.T != 0).any()] chsq_rlt.append(p_val(chi2_contingency(C1)[1])) # rename the column of the dataframe in order to merge p-vlue with crosstab b = pd.DataFrame(chsq_rlt).transpose() b["Non"] = b[0] b["Yep"] = "" b = b.drop([0], axis = 1) b = b.rename({0:"p-value"}) C = C.append(b) except: pass return C
## ③ ## ## 按照交叉表模板添加每个选项所对应的百分比 ## convert numbers into percentage def percent(X): A=X L=[[]] for i in range(0,len(A[0])): L[0].append("{:.1%}".format(A[0][i])) return np.array(L) def percentage1(question1,question2,Index_list,order): all_data=pd.DataFrame() p=chsq_test(question1,question2,Index_list) p=p.reset_index() List=p['index'].to_list()[:-1] if Text in Text_List: for i in range(1,len(p)-1): all_data=all_data.append(p[i:i+1]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:3].values / p[0:1].iloc[:,1:3].values), columns=p.iloc[:,1:3].columns)) all_data=all_data.fillna('vert'+'%'+List[i]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:3].values / p[i:i+1].iloc[:,1:3].values.sum()), columns=p.iloc[:,1:3].columns)) all_data=all_data.fillna('hori'+'%'+List[i]) all_data=all_data.append(p[len(p)-1:len(p)]) return all_data[order]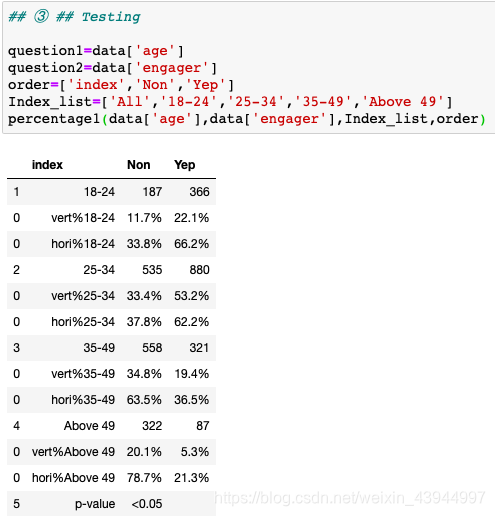
在计算每一个问题所对应的的百分比时,有两点需要注意。1. DataFrame在做行与行之间的计算时,需要将数据格式改为Series。 2. 将结果转化为百分比时,可以采用"{:.1%}".format(A)。2. 交叉表的生成 -- ② 简单三联表
其实三联表与二联表不用的地方在于我们需要将数据事先分为两组,生成两组索引相同的交叉表,然后再拼接起来。## ① ## ## 建立稍复杂的交叉表,且横向有两种维度(选项为两种维度的排列组合) # 1. 只需要将数据集按照是否参与营销互动分成两个数据集,分别利用type1()生成各自的交叉表 # 2. 将两个交叉表拼接起来 data1=data[data.engager=='No'] #根据是否参与营销互动,将数据分为的两部分 data1=data[data.engager=='Yes'] def combination1(question_str,Index_list): group = [] groupings = [(data1, y), (data2, y)] keyGroup = ['Non-Engagers / Recall', 'Engagers / Recall'] for element in groupings: group.append(chsq_test(element[0][question_str], element[1],Index_list)) result = pd.concat(group, keys = keyGroup, axis = 1) result = result.fillna(0) result.to_clipboard(excel=True) return(result)
## ② ## ## 计算行、列百分比 def percentage3(question,Text,Index_list): all_data=pd.DataFrame() p=combination1(question,Index_list) p=p[Text].reset_index() List=p['index'].to_list()[:-1] for i in range(1,len(p)-1): all_data=all_data.append(p[i:i+1]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:5].values / p[0:1].iloc[:,1:5].values), columns=p.iloc[:,1:5].columns)) all_data=all_data.fillna('vert'+'%'+List[i]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:5].values / p[i:i+1].iloc[:,1:5].values.sum()), columns=p.iloc[:,1:5].columns)) all_data=all_data.fillna('hori'+'%'+List[i]) all_data=all_data.append(p[len(p)-1:len(p)]) return all_data[['index','Non-Engagers / Recall','Engagers / Recall']]
2. 交叉表的生成 -- ③ 复杂二联表
当二联表中每个维度所涉及的分组越多时,越有可能会出现某些选项的统计结果为零的情况,但我们仍然要将这些结果展现在表格里。但这就意味着我们的交叉表中会有至少一列的数据全为0,那么这种情况我们是无法计算P-value的。所以以下的例子中不含P-value的结果。## ① ## ## 建立有分组的简单的交叉表,且横向一种维度(几个选项) def type2(question,fix,Index_list,col_name,options): a = pd.crosstab(question, fix, margins=True) for i in options: if i in a.columns: pass else: #如果某个选项没有数据,那就将其结果设为0 a[i]=0 a['Total positives'] = a['Much more positive']+a['Somewhat more positive']+a['No Change, was already positive'] a['Somewhat/ much more positive'] = a['Much more positive']+a['Somewhat more positive'] a['Total Negatives'] = a['Much more negative']+a['Somewhat more negative']+a['No change, was already negative'] a['Somewhat/ much more negative'] = a['Much more negative']+a['Somewhat more negative'] ## 将列名依照要求排列 a = a[col_name] a = a.fillna(0) a = a.reindex(Index_list) a.to_clipboard(excel=True) return a
## ② ## 计算P-value def chsq_test2(question,c,Index_list,col_name,options): chsq_rlt=[] C=type2(question,c,Index_list,col_name,options) C1=C.iloc[1:,:] # remove all zeroes try: C1=C1[(C1.T != 0).any()] chsq_rlt.append(p_val(chi2_contingency(C1)[1])) # rename the column of the dataframe in order to merge p-vlue with crosstab b = pd.DataFrame(chsq_rlt).transpose() b[col_name[0]] = b[0] b = b.fillna(" ") b = b.rename({0:"p-value"}) C = C.append(b) except: pass return C[col_name]def percentage2(question,c,Index_list,col_name,options): all_data=pd.DataFrame() p=chsq_test2(question,c,Index_list,col_name,options) p=p.reset_index() if 'p-value' in p.iloc[:,0].to_list(): List=p.iloc[:,0].to_list()[:-1] for i in range(1,len(p)-1): all_data=all_data.append(p[i:i+1]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:len(col_name)+1].values / p[0:1].iloc[:,1:len(col_name)+1].values), columns=p.iloc[:,1:len(col_name)+1].columns)) all_data=all_data.fillna('vert'+'%'+List[i]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:len(col_name)+1].values / p[i:i+1].iloc[:,[1,3]].values.sum()), columns=p.iloc[:,1:len(col_name)+1].columns)) all_data=all_data.fillna('hori'+'%'+List[i]) all_data=all_data.append(p[len(p)-1:len(p)]) else: List=p.iloc[:,0].to_list() for i in range(1,len(p)): all_data=all_data.append(p[i:i+1]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:len(col_name)+1].values / p[0:1].iloc[:,1:len(col_name)+1].values), columns=p.iloc[:,1:len(col_name)+1].columns)) all_data=all_data.fillna('vert'+'%'+List[i]) all_data=all_data.append(pd.DataFrame(percent(p[i:i+1].iloc[:,1:len(col_name)+1].values / p[i:i+1].iloc[:,[1,3]].values.sum()), columns=p.iloc[:,1:len(col_name)+1].columns)) all_data=all_data.fillna('hori'+'%'+List[i]) b=pd.DataFrame(columns=p.columns) b.loc[5] = 0 b[p.columns[0]] = "p-value" b = b.replace(0," ") all_data = all_data.append(b) col_list=[p.columns[0]] for j in col_name: col_list.append(j) return all_data[col_list]
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^