python能够输出结果却报错
为什么明明print输出了我要的,但是还是会报错呢?
print(name.split('=')[1])
print(time.split('=')[1])
name=name.split('=')[1]
time=time.split('=')[1]
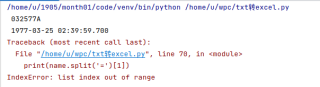
列表越界了呀,请确认name分割后得到的列表是否存在2个或以上的元素,如果只有一个元素的话索引为1时就会提示列表越界
你的输入中并没有=,所以切割出来下标1越界了
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/228225
- 这篇博客你也可以参考下:python程序没有报错但是运行没有任何结果怎么办?
- 除此之外, 这篇博客: python标准化预处理中的 为什么要进行标准化预处理? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
一般用到距离的机器学习问题,都需要进行标准化预处理。
例如:在分类问题中,不同特征的数量级和量纲不同。如果一个特征的数量级很大,就可能会湮没其他特征对于分类决策的影响。
所以需要统一数量级和去量纲,使其变成均值为0、方差为1的数据。
标准化预处理公式:(x−mean)/std(x - mean) / std(x−mean)/std,mean为均值,std为标准差
即数学中常见的: (x−μ)/σ(x-μ)/σ(x−μ)/σ
对于一维数据期望和标准差的计算(假设样本数为N):
μ∗=1N∑i=1Nxiμ^*=\frac{1}{N}\sum_{i=1}^{N}x_iμ∗=N1i=1∑Nxi
σ∗=1N∑i=1N(xi−μ∗)2σ^*=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_i-μ^*)^2}σ∗=N1i=1∑N(xi−μ∗)2
- 您还可以看一下 黄勇老师的Python从入门到实战 基础入门视频教程(讲解超细致)课程中的 子类不能继承父类的私有···小节, 巩固相关知识点