高维统计,控制FDR,多重检验
目前刚研一,导师推荐了一个高维统计的方向,是基于控制FDR的多重检验等的话题,我有些迷茫,想问问有没有有经验的小伙伴可以给我些建议和经验呢?
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/731672
- 这篇博客你也可以参考下:网站高并发,大流量问题处理以及解决办法
- 除此之外, 这篇博客: 使用分布外数据去除不需要的特征贡献,提高模型的稳健性中的 什么是对抗训练? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
为了理解为什么需要分布外数据增强训练来提高 DNN 的准确性和效率,首先要了解对抗性训练是什么以及为什么它很重要。
对抗性训练是指包含对抗性攻击图像作为其训练数据集的训练过程。对抗性训练的目标是让 DNN 更加健壮——让机器学习模型更不容易受到扰动的影响。
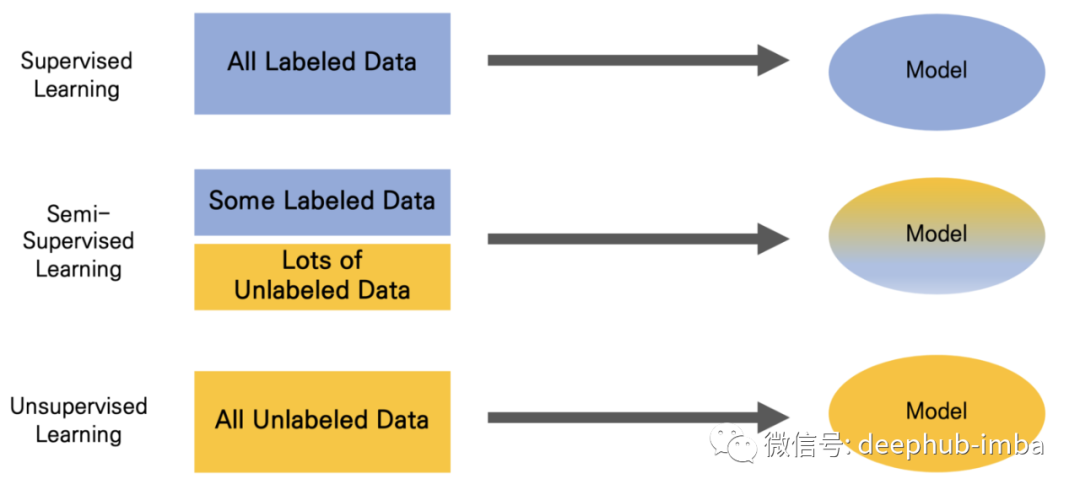
半监督学习方法
在对抗训练中需要比标准训练更多的数据集。所以仅使用标记数据是不够的,使用标记和未标记数据的混合指的就是半监督学习方法。
- 监督学习:仅使用标记数据作为其数据集
- 半监督学习:使用一些标记数据和大量未标记数据作为其数据集
- 无监督学习:仅使用未标记的数据作为其数据集
健壮和非健壮特征
由于人工智能的主要任务是模拟人类智能,因此图像识别过程也应该模拟人类。区分健壮特征和非健壮特征是不可或缺的,这是图像中两种有用的特征。
健壮的特征:人类可以感知的特征;与图像标签密切相关。
非健壮特征:人类无法感知的特征;与图像标签的相关性较弱。
已经证明,对抗性健壮性和标准准确性之间存在权衡关系。对抗性训练试图通过使非健壮特征不用于图像分类来解决这个问题。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^