用python 对csv数据进行预处理
要求根据提供的伪代码用python写出完整的代码。
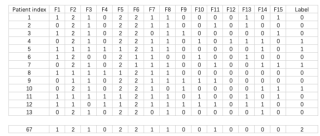
数据大概长这样
1.引用,伪代码如下(如果不足可以再补充)
2.删除‘lable’等于2的行,伪代码如下(csv的路径 可以空着)

3.得到'lable',伪代码如下

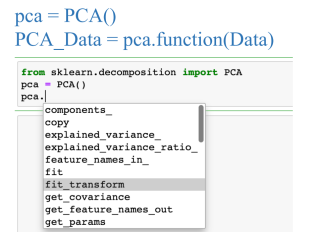
4.用pca方法合理降维,伪代码如下
5.绘图,伪代码如下()

import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 读取CSV文件
contents = pd.read_csv('path_of_csv')
# 删除label等于2的行
contents = contents[contents['Label'] != 2]
# 获取数据和标签
data = contents.iloc[:, 1:-1] # 获取第2列到倒数第2列的数据
labels = contents.iloc[:, -1] # 获取最后一列的标签
# 使用PCA方法进行降维
pca = PCA()
pca_data = pca.fit_transform(data)
# 绘制图形
plt.figure()
plt.plot(pca_data[:, 0], pca_data[:, 1], 'o')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
基于最新版ChatGPT4的回答,望采纳!!!有其他问题也可以询问我哦💕(最新版更智能,功能更加强大):
以下是完整的Python代码,实现了这些步骤:
从CSV文件中读取数据(假设数据在名为data.csv的文件中)。
删除标签为2的行。
获取标签列。
使用PCA方法将数据降至二维。
绘制结果图。
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 从CSV文件中读取数据
data = pd.read_csv('data.csv', header=None)
# 删除标签为2的行
data = data[data[0] != 2]
# 获取标签列
labels = data[0]
# 使用PCA方法将数据降至二维
pca = PCA(n_components=2)
data_pca = pca.fit_transform(data.drop(0, axis=1))
# 绘制结果图
plt.scatter(data_pca[:,0], data_pca[:,1], c=labels, cmap='viridis')
plt.colorbar()
plt.show()
注意,在上述代码中使用了pandas和matplotlib库,如果您还没有安装它们,可以通过以下命令进行安装:
python
pip install pandas matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 从CSV文件中读取数据
data = pd.read_csv('data.csv', header=None)
# 删除标签为2的行
data = data[data[0] != 2]
# 获取标签列
labels = data[0]
# 使用PCA方法将数据降至二维
pca = PCA(n_components=2)
data_pca = pca.fit_transform(data.drop(0, axis=1))
# 绘制结果图
plt.scatter(data_pca[:,0], data_pca[:,1], c=labels, cmap='viridis')
plt.colorbar()
plt.show()