随机生成一个有10个元素的成绩列表(数字在50-70之间),检查该成绩列表里是否有=60分的成绩,有的话就打印有,没有的话就打印没有\

请教解题思路,我写的错误离不离谱🥹刚学的循环,绕不过来了,这是要用嵌套吗
import random
scores = random.choices(range(50,71),k=10)
for score in scores:
if score == 60:
print("有")
break
else:
print("没有")
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/216499
- 这篇博客也不错, 你可以看下随机生成50个整数列表,并删除其中的奇数(列表初应用)
- 除此之外, 这篇博客: 50 行代码获取疫情实时数据,发送可视化图表到邮箱中的 数据获取 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
关于疫情的实时数据获取,我们可以通过爬虫直接去爬取(百度、腾讯、阿里)疫情数据平台上的实时数据。这边小编选择的爬取腾讯的实时数据。
腾讯的疫情实时数据展示平台的地址是:
https://news.qq.com/zt2020/page/feiyan.htm
经过对页面数据进行分析,小编发现实时疫情数据是通过 AJAX 进行传输的。通过抓包,找到了提供疫情数据的接口地址。单个省份的数据地址: "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=省份名" 例如: 湖北省的实时数据地址 url = "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=湖北" 湖南省的实时数据地址 url = "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=湖南" 单个城市的数据: "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=省份名&city=城市" 例如: 湖北武汉的实时数据地址 url = "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=湖北&city=武汉" 湖南长沙的实时数据地址 url = "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=湖南&city=长沙"知道了实时数据的地址,那么接下来通过 python 来获取数据就非常简单了,只需要几行代码,以湖北的数据为例,具体代码如下:
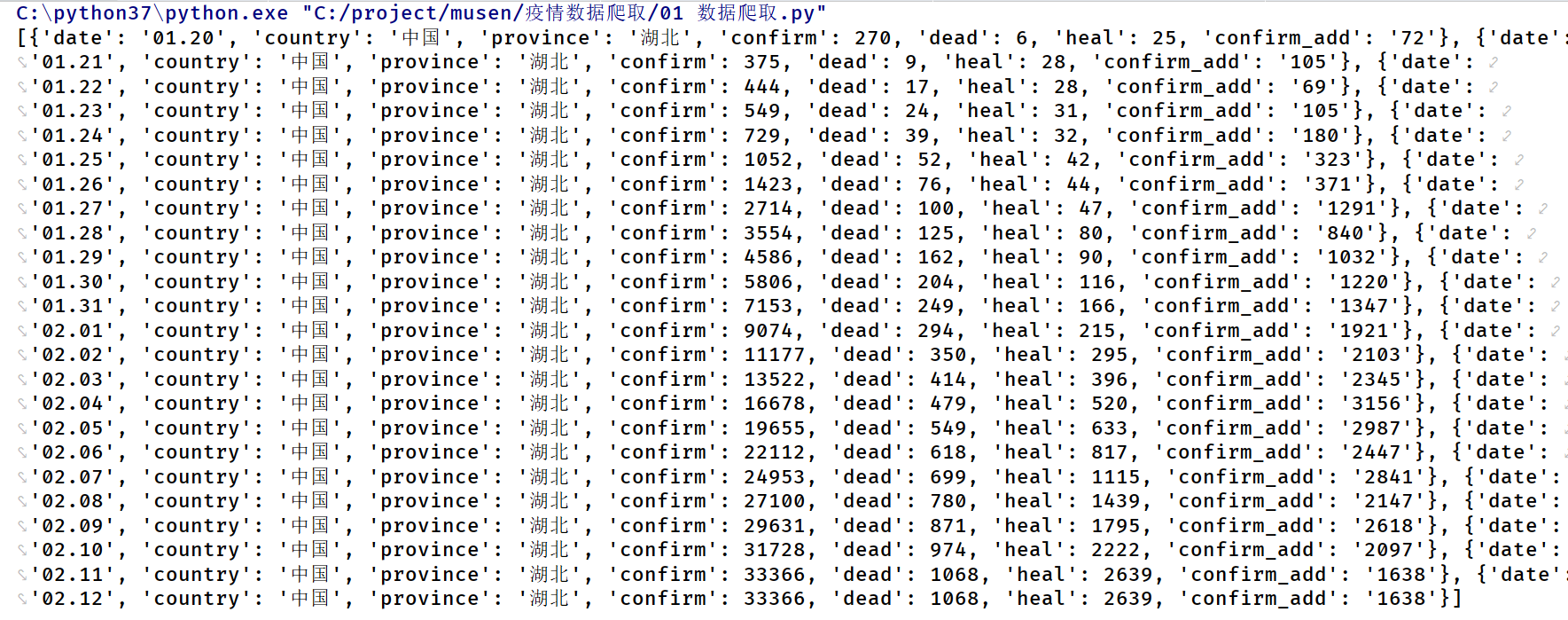
import requests # 数据url地址 url = "https://api.inews.qq.com/newsqa/v1/query/pubished/daily/list?province=湖北" # 发送请求获 response = requests.get(url=url) # 获取返回的数据 data = response.json()["data"] print(data)运行上面代码我们就能过获取到湖北省 1.20 到今天所有疫情的数据,结果如下:
1.不管有没有,都用个变量记录一下,不要直接打印
后面要判断这个变量
否则每个分你都打印一次,打印10次
2.删掉for循环,for循环完全是莫名其妙
你的列表在哪呢,根本没定义呀