为什么使用LSTM进行时间序列预测时,把学习率设置为0.0001是否合理?
使用LSTM进行时间序列预测时,把学习率设置为0.0001是否合理?
看情况而定。
初始值一般会稍微大一些,以加快收敛速度,后面随着训练拟合的加深,过大的学习率会导致loss震荡,所以一般后续会随着epoch加大而逐渐减少的。
而如果一开始就很小的话,训练速度会很慢,而且某些情况下一开始就很小的学习率会陷入局部最优(通俗比喻就是某个坑(局部最优)步子太小跨不过去)。
而这个也没有一个定值,说大于某个值就是过大,小于某个值就是过小。一般而言,初始值会在0.1~0.001之间(经验值,基本上也都是0.1,0.01,0.001这三个用的多,具体的看训练情况),而且不同的数据集这个值还不一样,得耐心调整然后看训练情况而定。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/748529
- 这篇博客也不错, 你可以看下时序预测 | MATLAB实现LSTM时间序列未来多步预测
- 除此之外, 这篇博客: 【预测模型】基于贝叶斯优化的LSTM模型实现数据预测matlab源码中的 LSTM 的核心思想 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
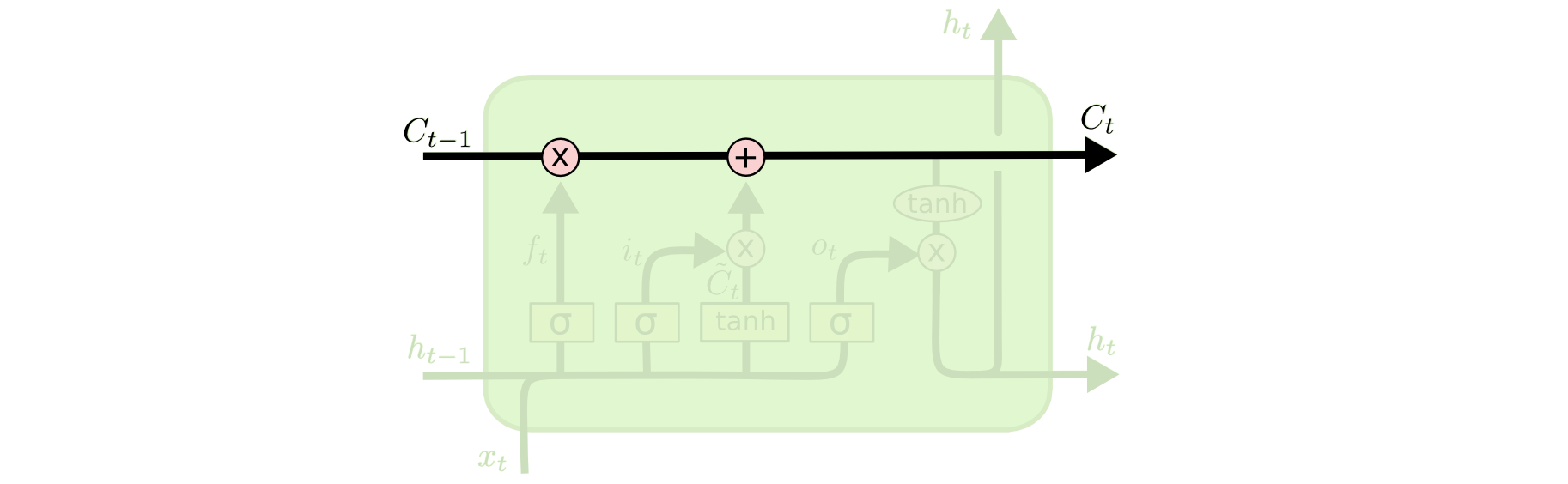
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。 细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
Paste_Image.png
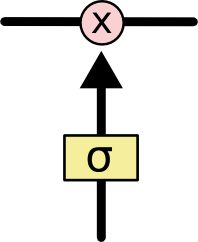
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
Paste_Image.png
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。