python爬取网页信息(主要为期刊影响因子、官网等),已有ISSN进行检索,但爬取过程找不到class该怎么办?
如第一张图所示,已经拥有ISSN,通过搜索框输入后,对结果栏(如第二张图所示)里面的一些指标包括影响因子、官网等进行提取,在通过request提取后,发现找不到这些指标对应的class,代码如第三张图所示,最终想得到的信息如第四张图所示。初学python,问题比较愚蠢还请见谅。
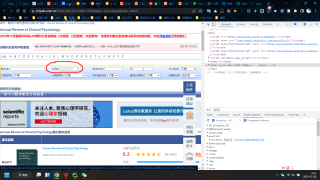
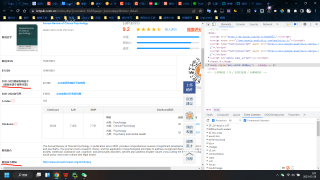
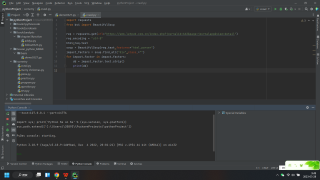

你需要现在网页html中看下那些指标因子的html结构是什么,才知道怎么提取。你的数据是在一个表格中,你可以先定位到表格的html,然后通过前后html标签来定位到你要解析的数据。代码如下,已成功提取,望采纳!
import requests
from bs4 import BeautifulSoup
import re
req = requests.get(url="https://www.letpub.com.cn/index.php?journalid=662&page=journalapp&view=detail")
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(html,'lxml')
#先定位数据所在的table
table_htmls = soup.find_all('table',attrs={'class':'table_yjfx'})
tr = table_htmls[1].find('td',string=re.compile("E-ISSN"))
print(tr.parent.next_sibling.contents[1].get_text())
td_2 = table_htmls[1].find('td',string="期刊官方网站")
if td_2:
print(td_2.next_sibling.a['href'])
最后成功提取你要的数据:
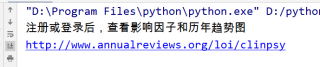
因为我这里没有登录,所以影响因子那里是图上的文字该回答引用ChatGPT
在爬取网页信息时,如果找不到对应的class,可以尝试以下几种方法:
1. 使用其他属性进行定位:除了class,还有id、name、tag等属性可以用来定位元素。可以通过浏览器的开发者工具查看元素的属性,找到一个唯一的属性进行定位。
2. 使用正则表达式:如果无法通过属性定位元素,可以尝试使用正则表达式来匹配需要的信息。可以使用re模块进行正则表达式的匹配。
3. 使用第三方库:如果以上方法都无法解决问题,可以尝试使用第三方库,如BeautifulSoup、pyquery等,这些库可以更方便地提取网页信息。
以下是使用BeautifulSoup库进行信息提取的示例代码:
python
import requests
from bs4 import BeautifulSoup
url = 'http://www.letpub.com.cn/index.php?page=journalapp&view=search'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
params = {
'searchname': 'ISSN',
'searchtype': 'exact',
'searchword': '0001-6233'
}
response = requests.post(url, headers=headers, data=params)
soup = BeautifulSoup(response.text, 'html.parser')
impact_factor = soup.find('td', text='影响因子').find_next_sibling('td').text.strip()
official_website = soup.find('td', text='官方网站').find_next_sibling('td').text.strip()
print('影响因子:', impact_factor)
print('官方网站:', official_website)
在这个示例中,我们使用了post方法向网站发送请求,并使用BeautifulSoup库解析返回的HTML文档。通过find方法找到对应的元素,再使用find_next_sibling方法找到下一个兄弟元素,最后使用text属性获取元素的文本内容。
不一定要找class标签,可以找其他标签作为抓取的定位,再根据正则去匹配试试。
- 这篇文章:PYthon作业通讯录文件中存有若干联系人的信息,每个联系人的信息由姓名和电话号码组成。 编写程序,完成以下功能: 输入姓名,若通讯录文件中存在,则讲该联系人信息输出; 也许有你想要的答案,你可以看看
- 除此之外, 这篇博客: 五分钟让你学会Python网络爬虫中的 入门Python其实很容易,但是我们要去坚持学习,每一天坚持很困难,我相信很多人学了一个星期就放弃了,为什么呢?其实没有好的学习资料给你去学习,你们是很难坚持的,这是小编收集的Python入门学习资料关注,转发,私信小编“资料”,即可免费领取!希望对你们有帮助 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
根据你提供的信息,我们可以使用Python的requests库和BeautifulSoup库来爬取网页信息并提取需要的内容。
首先,我们需要通过requests库来请求网页信息。这里提供一个示例代码:
import requests
url = 'http://mjl.clarivate.com/cgi-bin/jrnlst/jlresults.cgi?PC=MASTER&ISSN=' + ISSN
response = requests.get(url)
其中,ISSN是你想要查询的期刊的ISSN号码。这里将ISSN添加到了url中,并使用requests.get()方法来请求网页信息。请求成功后,我们可以对response进行解析。
接下来,我们可以使用BeautifulSoup库来解析网页信息,并查找我们需要的指标。这里提供一个示例代码:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# 获取官网信息
website = soup.find(string='Publisher')
if website:
website = website.parent.nextSibling.contents[0]
else:
website = ''
# 获取影响因子信息
impact_factor = soup.find(string='Impact Factor')
if impact_factor:
impact_factor = impact_factor.parent.nextSibling.contents[0]
else:
impact_factor = ''
这里使用BeautifulSoup库,将response.text作为输入,将网页信息解析为BeautifulSoup对象soup。然后使用soup.find()方法查找我们需要的指标,并提取其内容。在你的代码中可能会找不到class,但是使用soup.find()方法可以寻找其他标签属性,也可以使用正则表达式寻找内容。
最终,我们可以将需要的信息保存在一个字典中,代码如下:
journal_info = {
'ISSN': ISSN,
'website': website,
'impact_factor': impact_factor
}
将其返回即可。完整代码如下:
```python
import requests
from bs4 import BeautifulSoup
def get_journal_info(ISSN):
url = 'http://mjl.clarivate.com/cgi-bin/jrnlst/jlresults.cgi?PC=MASTER&ISSN=%27 + ISSN
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 获取官网信息
website = soup.find(string='Publisher')
if website:
website = website.parent.nextSibling.contents[0]
else:
website = ''
# 获取影响因子信息
impact_factor = soup.find(string='Impact Factor')
if impact_factor:
impact_factor = impact_factor.parent.nextSibling.contents[0]
else:
impact_factor = ''
# 返回结果字典
journal_info = {
'ISSN': ISSN,
'website': website,
'impact_factor': impact_factor
}
return journal_info
``