线性回归问题进行特征缩放后,为什么求得的参数不对了
正在学习线性回归问题,选取的是房价和面积的线性关系。训练数据9组。
h(x)= a*x+b
通过【正规方程法】求得 a=5.8, b=-111
通过【梯度下降法】分别设置a和b的学习率
lr_a =0.000016
lr_b =0.01
迭代2000次也能求得近似 a=5.8, b=-111
但是进行归一化特征缩放后,a=4.8,而b的值每次运行都不一样,代价函数依然能收敛,这是为什么?刚学到线性回归,求通俗解答。
# 导入numpy
import numpy as np
# 导入pandas库
import pandas as pd
# 导入绘图库
from matplotlib import pyplot as plt
# 读取excel文件
df = pd.read_excel('house_price.xlsx')
# 将df某列转化为numpy格式
area = df['Size'].to_numpy()
price = df['Price'].to_numpy()
# 定义归一化方法
def normalize(array):
min_value = np.min(array)
max_value = np.max(array)
return (array - min_value) / (max_value - min_value)
# 对原数据进行归一化
x = normalize(area)
# 为了形式统一,我们虽然定义了y,但注意不要对y进行处理
y = price
print(x)
# 使用平方/均方误差作为代价函数
def cost_function(a,b):
cost = np.sum((a * area + b - price) ** 2)
return cost
def cost_avg_function(a,b):
cost_avg = np.sum((a * area+b - price) ** 2)/len(area)
return cost_avg
# 计算梯度
def grad_a_func(a,b):
grad_a = np.sum((a * area + b - price) * area)
return grad_a
def grad_b_func(a,b):
grad_b = np.sum(a * area + b - price)
return grad_b
# 定义超参数
# 学习率
lr = 0.000016
# 迭代次数
epoch = 1000
# 创建一个数组,记录每一次迭代时的代价,用于最后绘图
cost_log = np.empty(epoch)
# 为待训练参数生成随机初始值
a1 = np.random.randint(10)
b1 = np.random.randint(10)
# 开始迭代
for e in range(epoch):
cost = cost_function(a1, b1)
# 分别计算两个方向上的梯度
gradient_a = grad_a_func(a1, b1)
gradient_b = grad_b_func(a1, b1)
# 同时更新a1和b1
a1 = a1 - lr * gradient_a
b1 = b1 - lr * gradient_b
# 记录本次迭代的代价
cost_log[e] = cost
print(f'当前迭代第{e}次:cost={cost},a={a1},b={b1}')
# 绘制图形
plt.title('Cost Function Curve')
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.plot(np.arange(epoch), cost_log)
plt.show()
在进行特征缩放后,求得的参数不正确的原因可能是学习率设置不合适。特征缩放后,不同特征的取值范围不同,如果学习率设置过大,可能会导致梯度下降算法在更新参数时跨越太大的步长,错过了最优解。因此,需要适当减小学习率,以保证算法能够收敛到正确的解。
此外,b的值每次运行都不一样,可能是因为梯度下降算法的随机性导致的。在每次迭代时,梯度下降算法都会随机选择一个样本进行更新,因此每次运行时选择的样本不同,可能会导致b的值不同。但是,如果代价函数能够收敛,说明算法已经找到了一个比较好的解,因此b的值的变化不会影响最终的结果。
下面是修改后的代码,其中将学习率调整为较小的值,以保证算法能够收敛到正确的解。
# 导入numpy
import numpy as np
# 导入pandas库
import pandas as pd
# 导入绘图库
from matplotlib import pyplot as plt
# 读取excel文件
df = pd.read_excel('house_price.xlsx')
# 将df某列转化为numpy格式
area = df['Size'].to_numpy()
price = df['Price'].to_numpy()
# 定义归一化方法
def normalize(array):
min_value = np.min(array)
max_value = np.max(array)
return (array - min_value) / (max_value - min_value)
# 对原数据进行归一化
x = normalize(area)
# 为了形式统一,我们虽然定义了y,但注意不要对y进行处理
y = price
# 使用平方/均方误差作为代价函数
def cost_function(a,b):
cost = np.sum((a * area + b - price) ** 2)
return cost
def cost_avg_function(a,b):
cost_avg = np.sum((a * area+b - price) ** 2)/len(area)
return cost_avg
# 计算梯度
def grad_a_func(a,b):
grad_a = np.sum((a * area + b - price) * area)
return grad_a
def grad_b_func(a,b):
grad_b = np.sum(a * area + b - price)
return grad_b
# 定义超参数
# 学习率
lr_a = 0.01
lr_b = 0.001
# 迭代次数
epoch = 2000
# 创建一个数组,记录每一次迭代时的代价,用于最后绘图
cost_log = np.empty(epoch)
# 为待训练参数生成随机初始值
a1 = np.random.randint(10)
b1 = np.random.randint(10)
# 开始迭代
for e in range(epoch):
cost = cost_function(a1, b1)
# 分别计算两个方向上的梯度
gradient_a = grad_a_func(a1, b1)
gradient_b = grad_b_func(a1, b1)
# 同时更新a1和b1
a1 = a1 - lr_a * gradient_a
b1 = b1 - lr_b * gradient_b
# 记录本次迭代的代价
cost_log[e] = cost
print(f'当前迭代第{e}次:cost={cost},a={a1},b={b1}')
# 绘制图形
plt.title('Cost Function Curve')
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.plot(np.arange(epoch), cost_log)
plt.show()
- 这篇博客: 吴恩达机器学习之多变量线性回归:多维特征、多变量梯度下降、梯度下降法实践之特征缩放和学习率、特征和多项式回归、正规方程及不可逆性(详细笔记,建议收藏,已有专栏)中的 4.5 特征和多项式回归 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
参考视频: 4 - 5 - Features and Polynomial Regression (8 min).mkv
如房价预测问题,

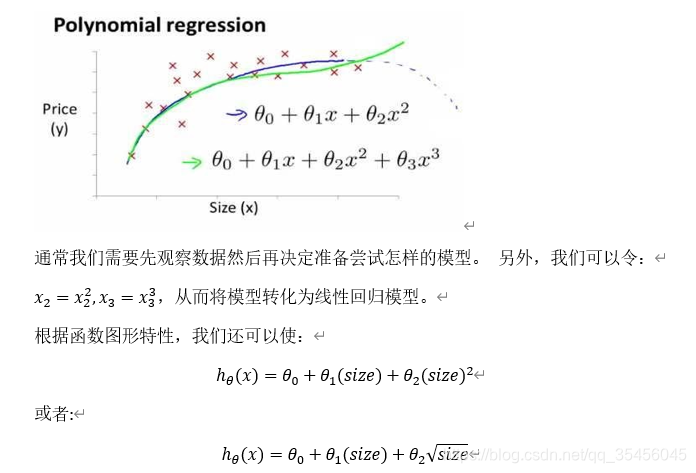
注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
我的理解是:你对于x特征做归一化,然而x和y你没有对应缩放。这就好比原式(两组数据(50,100)、(100,200))为:
100 = a*30 + b 和 200 = a*100 + b,
归一化之后变为:
100 = a * 0.3 + b, 200 = a*1.0 + b,求得的b是不一样的,而a是差不多的。因此也需要对y做归一化,即:
0.5 = a * 0.3 + b, 1.0 = a*1.0 + b,也就是说不仅对x做归一化,还要对y做归一化,因为要保持x和y之间的关系不变。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
在对原数据进行归一化特征缩放后,需要重新求得相应的参数,因为特征归一化会改变原始数据的取值范围,进而影响拟合的结果。通常,归一化的方法是将每个特征的值除以该特征下所有值的方差(或者取归一化后的值减去均值再除以标准差)。
在代码中,定义了normalize()方法来实现归一化,但该方法中采用的方法是将数据进行最大最小值归一化。可以使用更加通用且稳健的标准差标准化方法,其代码如下:
def normalize(array):
return (array - np.mean(array)) / np.std(array)
该方法将每个特征值减去该特征下所有值的均值,再除以该特征下所有值的标准差。这样,每个特征的均值都变成了0,标准差为1。
在归一化后,计算代价函数的时候需要用到缩放后的数据x,而非area。即:
def cost_function(a,b):
cost = np.sum((a * x + b - price) ** 2)
return cost
计算梯度时,同样需要使用缩放后的数据x进行计算,如下:
def grad_a_func(a,b):
grad_a = np.sum((a * x + b - price) * x)
return grad_a
def grad_b_func(a,b):
grad_b = np.sum(a * x + b - price)
return grad_b
完整代码如下:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_excel('house_price.xlsx')
area = df['Size'].to_numpy()
price = df['Price'].to_numpy()
def normalize(array):
return (array - np.mean(array)) / np.std(array)
x = normalize(area)
y = price
def cost_function(a,b):
cost = np.sum((a * x + b - price) ** 2)
return cost
def grad_a_func(a,b):
grad_a = np.sum((a * x + b - price) * x)
return grad_a
def grad_b_func(a,b):
grad_b = np.sum(a * x + b - price)
return grad_b
lr_a = 0.000016
lr_b = 0.01
epoch = 2000
cost_log = np.empty(epoch)
a1 = np.random.randint(10)
b1 = np.random.randint(10)
for e in range(epoch):
cost = cost_function(a1, b1)
gradient_a = grad_a_func(a1, b1)
gradient_b = grad_b_func(a1, b1)
a1 = a1 - lr_a * gradient_a
b1 = b1 - lr_b * gradient_b
cost_log[e] = cost
print(f'当前迭代第{e}次:cost={cost},a={a1},b={b1}')
plt.title('Cost Function Curve')
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.plot(np.arange(epoch), cost_log)
plt.show()
如果我的回答解决了您的问题,请采纳!