为什么我设置了utf-8 还是报错(标签-ar|关键词-cte)
为什么我设置了utf-8 还是报错
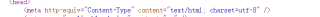
报错内容: UnicodeEncodeError: 'gbk' codec can't encode character '\xa9' in position 20868: illegal multibyte sequence
进程已结束,退出代码1
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import re
import requests
url = "https://www.umei.cc/bizhitupian/meinvbizhi/yangyanmeinv.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.44"
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
print(response.text)
response.encoding = 'utf-8' 换成如下代码看看:
response.encoding = response.apparent_encoding
14行去掉会怎样?
你的py文件要编码成utf8,而解析页面到底用什么语言,你要根据head来呀