关于#python#的问题,请各位专家解答!
这个报错怎么弄呀?我安装了dynamic包还是不行,还有我的index包下载不了

pip install dynamic 安装下
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7487617
- 这篇博客你也可以参考下:Python异常 IndexError
- 这篇博客也不错, 你可以看下Python异常 IndexError
- 除此之外, 这篇博客: 【python数据分析实战】电商打折套路解析(1)—— 各个品牌都有多少商品参加了双十一活动?中的 3. 双十一当天在售的商品占比情况 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
1) 获得商品的销售的时间跨度
因为每个商品的id是相同的,上一部获取的商品的销售日期就是为了这一步提取具体的开售和停售的日期
d1 = df[['id','date']].groupby(by = 'id').agg(['min','max'])['date'] #d = df.groupby(by = 'id').agg(['min','max'])['date'] print(d1)–> 输出结果为:(可以看看不加
['date']后的输出是什么)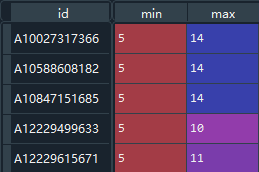
2) 获取双十一在售商品的id并进行数据清洗① 只要获取date字段中为11的id即可,注意这里可能存在相同的数据
id_11 = df[df['date'] == 11]['id'] print(id_11.is_unique)–> 输出结果为:(可以发现的确存在相同的商品数据)
False② 找到这个相同的数据
id_11 = data1[data1['date'] == 11]['id'] print(id_11.value_counts())–> 输出结果为:(只有id为A37637194605的商品相同)
A37637194605 2 A540024035676 1 A522560429591 1 A527945447650 1 A521181542916 1 .. A526383253767 1 A40530583093 1 A529008131128 1 A520976852456 1 A528413776238 1 Name: id, Length: 2335, dtype: int64③ 查看一下这个重复的数据是什么样子的
id_A37637194605 = df[df['id'].str.contains('A37637194605') & (df['date'] == 11)] print(id_A37637194605)–> 输出结果为:(根据输出发现,这两条数据是一样的,属于重复数据,可以直接删除)
update_time id title price 店名 date 2016-11-11 A37637194605 兰芝水衡致润保湿乳120ML 补水滋养长效保湿 亮肤控油 女 护肤 235.0 兰芝 11 2016-11-11 A37637194605 兰芝水衡致润保湿乳120ML 补水滋养长效保湿 亮肤控油 女 护肤 235.0 兰芝 11④ 去除重复数据
id_11.drop_duplicates(inplace=True) print(id_11.value_counts())–> 输出结果为:(数据清洗完毕)
A540024035676 1 A536839755447 1 A527945447650 1 A521181542916 1 A540685584434 1 .. A526383253767 1 A40530583093 1 A529008131128 1 A520976852456 1 A528413776238 1 Name: id, Length: 2335, dtype: int64★★★★★上面的判断是否有重复值、查看重复值、去除重复值,只是为了熟悉一下处理重复值的流程,熟练了之后可以直接使用如下的代码进行替换或者验证结果
id_11 = df[df['date'] == 11]['id'].unique() m = len(d1) m_11 = len(id_11) m_pre = m_11/m print("双十一当天参加活动的商品为{}个,占比为{:.2f}%".format(m_11, m_pre*100)) print('品牌总数为{}个\n'.format(len(data1['店名'].unique())),data1['店名'].unique())–> 输出结果为:(与上面的
Name: id,Length: 2335数据相符合,使用unique()方法最后获得的naddary数组,可以用来构建DataFrame数据)双十一当天参加活动的商品为2335个,占比为66.68% 品牌总数为22个 ['相宜本草' '佰草集' '欧莱雅' '美宝莲' '玉兰油' '蜜丝佛陀' '悦诗风吟' 'SKII' '兰芝' '妮维雅' '自然堂' '倩碧' '欧珀莱' '美加净' '雅诗兰黛' '资生堂' '兰蔻' '雅漾' '雪花秀' '植村秀' '薇姿' '娇兰']
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^