LSTM-VAE用来预测数据,结果很诧异,不知道哪里出了问题。
输入的数据集为单一的用户用电数据,单列的时间预测数据格式如下图所示:
https://imgse.com/i/ppdkAc6
其中每一个列代表一个居民的用电,想要通过编码器重构数据进行预测。代码如下所示:
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import sys
# 将LSTM和自动编码器-解码器结合起来,可以用LSTM作为自动编码器的编码器,将输入序列编码为隐藏状态,
# 然后使用LSTM的反向传播将隐藏状态解码为输出序列。这种方法可以用于对序列数据进行特征提取和重建
class LSTMAutoencoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(LSTMAutoencoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# LSTM encoder input_size = 10 hidden_size = 5
self.encoder = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True)
# LSTM decoder 5 10
self.decoder = nn.LSTM(input_size=hidden_size, hidden_size=input_size, num_layers=1, batch_first=True)
def forward(self, x):
# 编码
encoded, (hidden, cell) = self.encoder(x)
# 解码
decoded, _ = self.decoder(encoded) #[21,10,1]
return decoded
# Usage example
input_size = 1
hidden_size = 16
batch_size = 10
sequence_length = 50
LR = 0.005
EPOCH = 1000
# Create random input data
# 读取文件中的所有数据
all_data = pd.read_csv("./dataset/LD2011_2014.csv", index_col=0, parse_dates=[0])
all_data = all_data.replace(0.000000, np.nan) # 填充
# 找到一户不不含有nan的数据
one_home_data = all_data["MT_158"].resample("W").sum()
print(np.any(one_home_data == np.nan)) # 打印False代表没有nan
plt.figure()
plt.plot(one_home_data, label='test') # 横纵坐标
one_home_data = torch.from_numpy(one_home_data.astype('float32').values.reshape(-1, batch_size, input_size)) #[21,10,1]
model = LSTMAutoencoder(input_size=input_size, hidden_size=hidden_size)
print(model)
loss_function = nn.MSELoss() #损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=LR) #优化器
for epoch in range(EPOCH):
reconstruction = model(one_home_data) #[1,21,1]
loss = loss_function(reconstruction, one_home_data)
loss.backward() # 反向传播,计算当前梯度
optimizer.step()
optimizer.zero_grad()
if epoch % 100 == 0:
print('Epoch :', epoch, '|', 'train_loss:%.4f' % loss.data)
在预测完之后,每次decoded输出的结果都很小,与原始数据差距很大,
每次的均方误差损失上亿,不知道是模型哪里设置的不合适,还是哪里出了问题,
是不是要在模型组以后加一个全连接层还是什么。原始的数据经过处理后,大概是这样:
https://imgse.com/i/ppdkd4s
每一个数据都很大,但是经过编码器解码器重构之后,得到的数据都没有超过1的,是不是经过激活函数归一化了啊??我不理解
经过解码后的数据decoded的数据如下图所示:https://imgse.com/i/ppdkrvV
原始数据画出来的图示这样子的:https://imgse.com/i/ppdk6DU
所以不知道问题出在了哪里,请指导。
- 文章:百题突击2:1.在模型评估过程中,过拟合和欠拟合具体指什么现象 2.降低过拟合和欠拟合的方法 3.L1和L2正则先验分别服从什么分布 4.对于树形结构为什么不需要归一化? 中也许有你想要的答案,请看下吧
- 除此之外, 这篇博客: 百题突击2:1.在模型评估过程中,过拟合和欠拟合具体指什么现象 2.降低过拟合和欠拟合的方法 3.L1和L2正则先验分别服从什么分布 4.对于树形结构为什么不需要归一化?中的 1.在模型评估过程中,过拟合和欠拟合具体指什么现象 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
过拟合(overfitting)指的是模型在训练数据是表现非常好,但是在验证集上表现特别差。
欠拟合(underfitting)指的是是模型在训练数据和验证集上表现都比较差。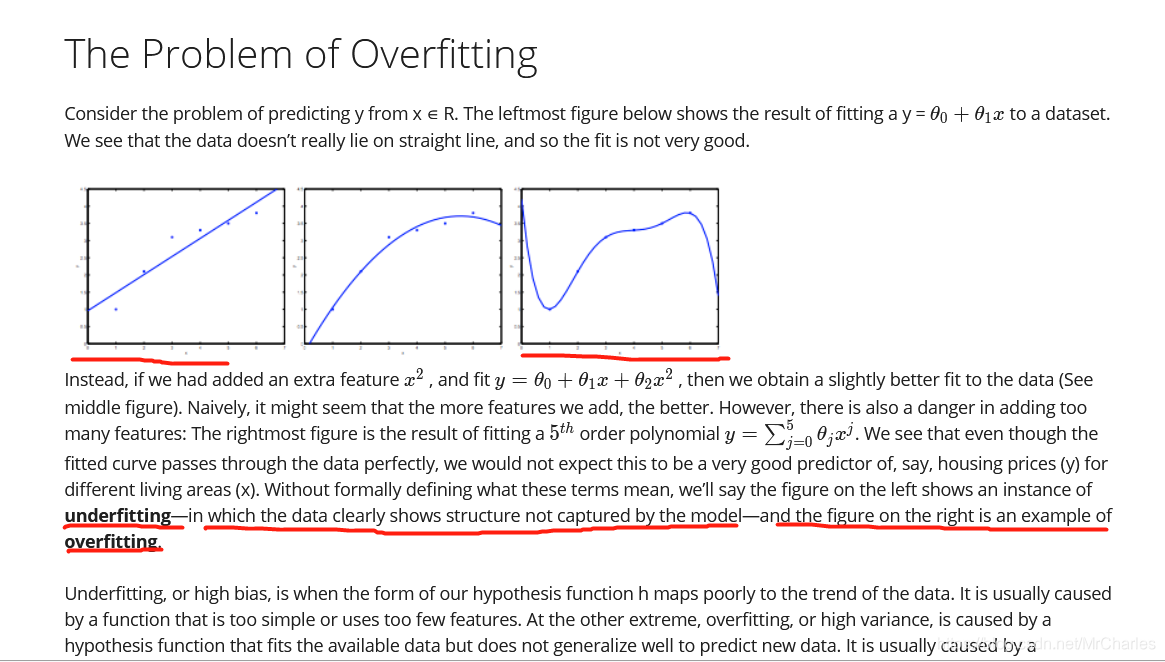
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^