flink jobmanager jvm metaspace 一直增长
部署说明:使用flink on k8s
启动模式:使用session模式启动(JobManager一直存在,TaskManager资源动态分配)
问题描述:当我反复次提交flink示例代码./examples/streaming/WordCount.jar ,JobManager的JVM Metaspace空间将一直增大,直到报错。Pod自动重启。

根据你的描述,我猜测你的问题是:
使用 session 模式启动 Flink on Kubernetes,当多次提交 Flink 示例代码后,JobManager 不稳定,出现故障。
这可能是由于以下原因导致的:
Kubernetes 集群资源不足。如果 Kubernetes 集群的资源不足,例如内存和 CPU,可能导致 JobManager 不稳定。在尝试重新启动 JobManager 之前,您可能需要验证 Kubernetes 集群的资源使用情况并增加资源。
由于提交的多个任务在 Flink 中运行和调度,导致 Flink 集群资源不足。如果你反复提交 Flink 示例代码,可能会导致 Flink 集群的负载过重,使得 JobManager 不稳定。您可以考虑在 Flink 安装中使用更多的 TaskManager,并增加 Kubernetes 集群的资源配额。
可能存在代码或配置问题。如果您的代码存在问题或配置不正确,可能会导致 JobManager 不稳定,需要您检查日志以查找问题。
为解决此问题,你可以采取以下步骤:
验证 Kubernetes 集群的资源使用情况,并增加资源限制。
使用更多的 TaskManager,并增加 Kubernetes 集群的资源配额来增加 Flink 集群的负载能力。
检查日志,定位问题,可以使用 Flink 的 Web UI 或 Kubectl logs 命令查看 Flink 集群的详细日志。
升级 Flink 的版本,如果存在已知的问题,则更新到最新的版本可能会有所帮助。
希望以上步骤可以帮助你解决问题。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章讲的很详细,请看:flink命令行提交jar任务(Caused by : java.lang.ClassNotFoundException: org.myorg.quickstart.StreamingJob)
- 除此之外, 这篇博客: Flink - Java篇中的 JobManager 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
控制一个应用程序执行的主进程,一个应用程序只会对应一个JobManager。
一个应用程序包括:
- 作业图 - JobGraph
- 逻辑数据流图 - logical dataflow graph
- 含有打包完的所需资源的Jar包
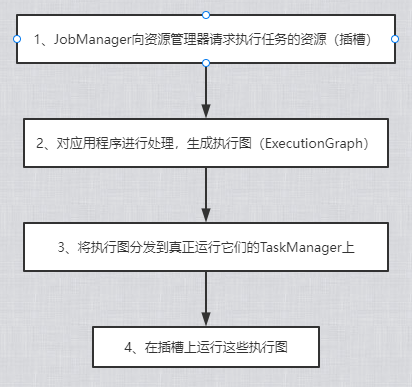
大致的流程是这样
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^