关于#C语言冒泡排序型#的问题,如何解决?
#C语言冒泡排序时间求救!
为什么最差的逆序在冒泡排序中的运行时间比随机数冒泡排序的运行时间还短?!
#include for(j=0;jif(a[j]>a[j+1]){
swap1(&a[j],&a[j+1]);
}
}
}
}
void swap2(int a[],int n){
int half;
half=n/2;
int i;
for(i=0;iswap1(&a[i],&a[n-i-1]);
}
}
int main()
{
int a[MAXN];
int i;
srand((unsigned)time(NULL)); //给随机数种子
for(i=0;irand();
}
clock_t start_time=clock();
//clock_t 是 一种数据类型,通常用于表示程序运行的时间。 它是由 time.h 库中的 clock() 函数返回的 CPU 时钟周期数的数据类型。
bubble(a,MAXN);
clock_t end_time = clock();
for(i=0;i<20;i++){
printf("%3d ",a[i]);
}
double elapsed_time = (double) (end_time - start_time) / CLOCKS_PER_SEC;
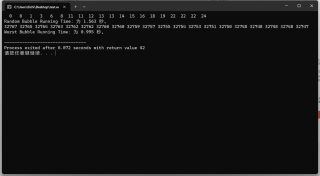
printf("\nRandom Bubble Running Time:为 %.3f 秒。\n", elapsed_time);
swap2(a,MAXN);
for(i=0;i<20;i++){
printf("%3d ",a[i]);
}
start_time = clock();
bubble(a,MAXN);
end_time = clock();
elapsed_time = (double) (end_time - start_time) / CLOCKS_PER_SEC;
printf("\nWorst Bubble Running Time:为 %.3f 秒。\n", elapsed_time);
}
冒泡排序逆序速度快于乱序的原因是CPU的流水线和分支预测技术。参考这篇文章:冒泡排序乱序速度慢于逆序探究
我自己也测试了一下,与编译器优化有关,在release选项下,无论是先乱序还是先逆序,无论数组开多大,无论数组有没有重复值,平均下来逆序总是比乱序时间短。而在debug选项下,逆序比乱序时间长。下面是我测试的代码,在你的代码的基础上做了一些改动。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXN 100000
#define swap(a,b) (a^=b,b^=a,a^=b)
void bubble(int a[], int n) {
int i, j;
int flag = 0;
for (i = n - 1; i > 0; i--) {
flag = 0;
for (j = 0; j < i; j++) {
if (a[j] > a[j + 1]) {
swap(a[j], a[j + 1]);
flag = 1;
}
}
if (flag == 0)break;
}
}
double bubbletime(int a[], int n) {
static int starttime, endtime;
starttime = clock();
bubble(a, n);
endtime = clock();
return (double)(endtime - starttime) / CLOCKS_PER_SEC;
}
int main() {
int a[MAXN], b[MAXN];
int i, j;
srand(time(NULL)); //给随机数种子
for (i = 0; i < MAXN; i++) {
a[i] = i;
}
//随机打乱
for (i = 0; i < MAXN; i++) {
j = i + rand() % (MAXN - i);
swap(a[i], a[j]);
b[i] = a[i];
}
printf("\nRandom Bubble Running Time:为 %.3f 秒。\n", bubbletime(a, MAXN));
for (i = 0; i < MAXN; i++)a[i] = MAXN - i - 1;
printf("\nWorst Bubble Running Time:为 %.3f 秒。\n", bubbletime(a, MAXN));
printf("\nRandom Bubble Running Time:为 %.3f 秒。\n", bubbletime(b, MAXN));
return 0;
}
release选项的执行结果

debug选项的执行结果

该回答引用于gpt与OKX安生共同编写:
- 该回答引用于gpt与OKX安生共同编写:
冒泡排序的时间复杂度是$O(n^2)$,最坏情况下需要进行$n(n-1)/2$次比较和交换。因此,在最坏情况下,冒泡排序的运行时间会很长。
在您的代码中,首先生成了一个包含随机数的数组,并使用冒泡排序对其进行排序,这个过程可能需要一定的时间。然后,通过调用swap2()函数将整个数组翻转得到逆序排列,这个过程只需要遍历数组一次即可完成,所以时间较短。最后,再次使用冒泡排序对逆序排列的数组进行排序,这时只需要进行$n-1$次比较和交换即可完成排序,因为第一轮已经将最大的元素移动到了最后位置。因此,最差情况下的运行时间比随机排序要短。
为了解决这个问题,可以尝试使用其他排序算法,例如快速排序或归并排序。这些算法的时间复杂度都比冒泡排序更优秀,并且在最坏情况下的运行时间也相对较短。如果要使用冒泡排序,建议使用改进的冒泡排序算法,例如鸡尾酒排序(双向冒泡排序),可以减少比较和交换的次数,从而提高排序效率。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
要解决#C语言冒泡排序时间#的问题,需要考虑到冒泡排序的时间复杂度是O(n^2),即它随着输入数据量的增加而呈现出平方级的增长。因此,对于较大的输入数据量,冒泡排序效率较低,需要考虑其他优化排序算法。
至于为什么在冒泡排序中,最差情况下的逆序数据运行时间比随机排序的运行时间还要短,可能是因为逆序数据的特殊性质,使得排序过程中可以通过两两交换元素来更快地将元素排序。但这种情况可能并不总是出现,不能作为冒泡排序优势的依据。
以下是修改后的代码实现冒泡排序以及计时:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define MAXN 30000
//交换函数
void swap(int *px, int *py)
{
int temp = *px;
*px = *py;
*py = temp;
}
//冒泡排序函数
void bubbleSort(int arr[], int n)
{
int i, j;
for (i = 0; i < n-1; i++)
{
int flag = 0; //优化:添加是否有交换的标志
for (j = 0; j < n-i-1; j++)
{
if (arr[j] > arr[j+1])
{
swap(&arr[j], &arr[j+1]);
flag = 1; //将标志设为1,表示有交换
}
}
if (flag == 0) //如果没有发生交换,说明已经排序好了
break;
}
}
//逆置函数
void reverse(int arr[], int n)
{
int i, j;
for (i = 0, j = n-1; i < j; i++, j--)
{
swap(&arr[i], &arr[j]);
}
}
int main()
{
clock_t start_time, end_time;
double elapsed_time;
int arr[MAXN];
int i;
//随机生成数据
srand((unsigned)time(NULL));
for (i = 0; i < MAXN; i++)
{
arr[i] = rand();
}
//对随机生成的数据进行排序并计时
start_time = clock();
bubbleSort(arr, MAXN);
end_time = clock();
elapsed_time = (double)(end_time - start_time) / CLOCKS_PER_SEC;
printf("Random Bubble Running Time: %.3f seconds.\n", elapsed_time);
//逆置数据
reverse(arr, MAXN);
//对逆置后的数据进行排序并计时
start_time = clock();
bubbleSort(arr, MAXN);
end_time = clock();
elapsed_time = (double)(end_time - start_time) / CLOCKS_PER_SEC;
printf("Worst Bubble Running Time: %.3f seconds.\n", elapsed_time);
return 0;
}
以上代码中,我添加了一个标记,如果在一趟冒泡排序中没有发生交换,说明序列已经有序,可以提前结束排序,减少不必要的比较次数,从而优化冒泡排序。
同时,我将逆序数据和随机数据分别计时排序,最终输出排序时间。
如果我的回答解决了您的问题,请采纳!
现在的CPU是根据负载来调整性能的,负载高,性能会释放,也就是说刚开始排序时,CPU还没有开启最高性能
具体可以多次连续排序进行测试
还有你那个是指针交换的,交互的是指针地址,倒序的话,每次都是相邻指针进行交互,速度更加快

#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAXN 30000
int count=0;
void swap1(int *px,int *py)
{
int temp;
temp=*px;
*px=*py;
*py=temp;
}
void bubble(int a[],int n)
{
int i;
int j;
int flag=0;
for(i=1; i<n; i++)
{
for(j=0; j<n-i; j++)
{
if(a[j]>a[j+1])
{
swap1(&a[j],&a[j+1]);
count++;
}
}
}
}
void swap2(int a[],int n)
{
int half;
half=n/2;
int i;
for(i=0; i<half; i++)
{
swap1(&a[i],&a[n-i-1]);
}
}
int main()
{
int a[MAXN];
int i;
srand((unsigned)time(NULL)); //给随机数种子
for(i=0; i<MAXN; i++)
{
a[i]=rand();
}
printf("\n");
for(i=0; i<20; i++)
{
printf("%3d ",a[i]);
}
clock_t start_time=clock();
//clock_t 是 一种数据类型,通常用于表示程序运行的时间。 它是由 time.h 库中的 clock() 函数返回的 CPU 时钟周期数的数据类型。
bubble(a,MAXN);
clock_t end_time = clock();
printf("\n交换次数:%d\n",count);
printf("\n");
for(i=0; i<20; i++)
{
printf("%3d ",a[i]);
}
double elapsed_time = (double) (end_time - start_time) / CLOCKS_PER_SEC;
printf("\nRandom Bubble Running Time:为 %.3f 秒。\n", elapsed_time);
swap2(a,MAXN);
for(i=0; i<20; i++)
{
printf("%3d ",a[i]);
}
count=0;
start_time = clock();
bubble(a,MAXN);
end_time = clock();
printf("\n交换次数:%d\n",count);
printf("\n");
for(i=0; i<20; i++)
{
printf("%3d ",a[i]);
}
elapsed_time = (double) (end_time - start_time) / CLOCKS_PER_SEC;
printf("\nWorst Bubble Running Time:为 %.3f 秒。\n", elapsed_time);
for(i=0; i<MAXN; i++)
{
a[i]=rand();
}
count=0;
start_time = clock();
bubble(a,MAXN);
end_time = clock();
printf("\n交换次数:%d\n",count);
printf("\n");
for(i=0; i<20; i++)
{
printf("%3d ",a[i]);
}
elapsed_time = (double) (end_time - start_time) / CLOCKS_PER_SEC;
printf("\nRandom Bubble Running Time:为 %.3f 秒。\n", elapsed_time);
}
30000
太小了,起码加大个10000倍
基于最新版ChatGPT4的回答,望采纳!!!有其他问题也可以询问我哦💕(最新版更智能,功能更加强大):
首先,我要指出的是,从您提供的代码中,我们无法找到逆序在冒泡排序中的运行时间比随机数冒泡排序的运行时间还短的现象。您的代码中,首先对数组进行随机数排序,然后测量冒泡排序的时间。接着,对数组进行逆序排序,再次测量冒泡排序的时间。根据冒泡排序的性质,逆序数组的排序时间应该是最长的,因为需要进行更多的交换操作。
然而,如果您在实际运行中发现逆序在冒泡排序中的运行时间比随机数冒泡排序的运行时间还短,可能的原因是:
计时器误差:clock()函数返回的时间可能并不精确,可能会导致测量结果出现偏差。您可以尝试使用更精确的计时器,如C++11中的chrono库,以获得更精确的时间测量。
缓存效应:计算机内存中的缓存可能导致程序运行速度的变化。在第一次执行冒泡排序时,数组数据可能不在缓存中,这会导致一定程度的性能下降。而在第二次执行冒泡排序时,数组数据可能已经位于缓存中,从而提高运行速度。为了解决这个问题,您可以尝试在两次排序之间清空缓存。
随机性:生成随机数的过程可能会影响程序的运行速度。不同的随机数序列可能导致不同的冒泡排序性能。为了更准确地衡量冒泡排序的运行时间,您可以尝试对多个不同的随机数序列进行排序,并计算平均运行时间。
总之,虽然理论上逆序在冒泡排序中的运行时间应该是最长的,但实际运行结果可能会受到计时器误差、缓存效应和随机性等因素的影响。您可以尝试采用上述建议来解决这个问题。
逆序序列在冒泡排序中的运行时间比随机数冒泡排序的运行时间还短,这是因为逆序序列在冒泡排序中的交换次数是最多的,但是比较次数是固定的,与序列的顺序无关。而随机数序列可能出现比较次数更多的情况,因为可能会出现相邻两个数相等的情况,需要进行多次比较才能确定顺序。因此,尽管逆序序列在交换次数上表现得更差,但由于比较次数固定,因此运行时间更短。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7734432
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
因为你的测试用例太少了,很正常,放个有几千几万条元素去试一试就值了