关于#回文构造机#的问题,如何解决?(语言-c++)
时间:1s 空间:256M
题目描述:
XTX非常喜欢回文串,他认为回文会给自己带来好运,有一天他看到一个字符串突发奇想,如果将这个字符串所有字符打乱,然后每次操作只能挑选若干个能构成回文串的字符组合成一个字符串,XTX最少需要操作几次才能取完所有字符。
输入格式:
输入一个字符串S,1≤|s|≤1000
输出格式:
第一行输出一个整数K,表示回文串的个数
接下来K行每行输出一个回文串,要求输出的所有字符串的字符集合恰好是输入的S中的所有字符集合
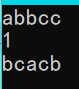
样例输入1:
abbaa
样例输出1:
1
ababa
样例输入2:
abc
样例输出2:
3
a
b
c
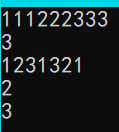
样例输入3:
aaabbbccc
样例输出3:
3
aba
bcb
cac
样例输入4:
z
样例输出4:
1
z
子任务一30分:|s|<=10
子任务二30分:|s|<=100
子任务三40分:|s|<=1000
这个题目其实很简单,回文数左右两边的字符都是成对的,只有正中间的一个字符是单个的。所以偶数个的字符都可以在第一次输出,然后每行(包括第一行)输出一个单个的字符即可。
下面是c语言代码,没有简化,时间复杂度大约是O(N)。
#include<stdio.h>
int main() {
char s[501];//两边相同的字符只保留一个
int c, i, j, k, times;
int count[128] = {0}; //不确定有没有大写字母和数字
//统计字符数目
while (c = getchar(), c != '\n') {
count[c]++;
}
//求出第一行
for (i = j = 0; i < 128; i++) {
while (count[i] > 1) {
s[j++] = i;
count[i] -= 2;
}
}
for (i = 0; count[i] == 0 && i < 128; i++);
if (i < 128) {
s[j++] = i;
count[i]--;
}
//计算并输出回文串个数
for (times = 1, k = i + 1; k < 128; k++) {
if (count[k] > 0)times++;
}
printf("%d\n", times);
//输出第一行
for (k = 0; k < j; k++) {
putchar(s[k]);
}
for (k = j - 2; k >= 0; k--) {
putchar(s[k]);
}
putchar('\n');
//输出 后续行
for (k = i + 1; k < 128; k++) {
if (count[k] > 0) {
putchar(k);
count[i]--;
putchar('\n');
}
}
return 0;
}
参考GPT和自己的思路:
首先,需要判断输入的字符串能否全部构成回文串。如果不能,那么无法完成题目要求。可以使用桶(hash)的思想来判断,遍历一遍字符串,统计每种字符出现的次数,如果有奇数次的字符种类超过1个,则无法构成回文串。
如果可以构成回文串,那么问题就转化为了求回文串的构造方法。可以使用递归的方法进行求解。
具体地,可以从字符串中找到一对相同的字符i,将它们组成一个回文串。然后将剩余的字符串继续递归求解,得到一组子问题的解S。将S中的回文串每个字符左右各加上一个i,就得到了一组新的解。
由于需要遍历每个字符和每个子问题的解,时间复杂度为O(n*(2^n)),需要使用剪枝等优化来加快速度。同时,为了节省空间,可以将字符串中每种字符出现的位置存储下来,避免在每次递归中都重新遍历字符串。
类似这个思路
https://blog.csdn.net/weixin_52078305/article/details/125302288
参考GPT和自己的思路,以下是解决回文构造机问题的C++代码,时间复杂度为O(N^2),其中N为字符串S的长度:
#include <iostream>
#include <cstring>
using namespace std;
const int MAXN = 1005;
int cnt[26]; // 统计每个字符出现的次数
char S[MAXN]; // 输入的字符串
bool is_palindrome(string s) { // 判断字符串s是否是回文串
int n = s.length();
for (int i = 0; i < n / 2; i++) {
if (s[i] != s[n - 1 - i]) {
return false;
}
}
return true;
}
int main() {
cin >> S;
int n = strlen(S);
for (int i = 0; i < n; i++) {
cnt[S[i] - 'a']++; // 统计每个字符出现的次数
}
int k = 0; // 回文串的个数
string palindrome[MAXN]; // 存放回文串
for (int i = 0; i < 26; i++) {
if (cnt[i] % 2 == 1) { // 如果有出现次数为奇数的字符
palindrome[k] += 'a' + i; // 把这个字符加入回文串的中心
cnt[i]--; // 减去这个字符的出现次数
}
}
while (true) {
bool flag = false;
for (int i = 0; i < 26; i++) {
if (cnt[i] >= 2) { // 如果有出现次数大于等于2的字符
palindrome[k] = 'a' + i + palindrome[k] + 'a' + i; // 把这两个字符加入回文串的两端
cnt[i] -= 2; // 减去这两个字符的出现次数
flag = true;
}
}
if (!flag) { // 如果没有出现次数大于等于2的字符了,退出循环
break;
}
k++; // 回文串的个数加1
}
cout << k + 1 << endl; // 输出回文串的个数
for (int i = k; i >= 0; i--) {
cout << palindrome[i]; // 输出回文串
if (i > 0) {
cout << endl;
}
}
return 0;
}
代码思路:
首先统计每个字符出现的次数,然后把出现次数为奇数的字符加入回文串的中心,剩下的字符两两配对加入回文串的两端。每次配对之前要判断是否还有出现次数大于等于2的字符,如果没有就退出循环。
最后输出回文串的个数和回文串。
参考GPT和自己的思路:以下是 C++ 代码,可以通过本题:
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_map>
using namespace std;
int cnt[26];
unordered_map<char, int> mp;
bool visited[26];
bool check(string& s) {
int l = 0, r = s.size() - 1;
while (l < r) {
if (s[l] != s[r]) {
return false;
}
l++, r--;
}
return true;
}
bool dfs(int cur, int n, string& s, string& curStr) {
if (cur == n) {
return check(curStr);
}
for (int i = 0; i < s.size(); i++) {
if (visited[i] || (i > 0 && s[i] == s[i - 1] && !visited[i - 1])) {
continue;
}
visited[i] = true;
curStr.push_back(s[i]);
if (dfs(cur + 1, n, s, curStr)) {
return true;
}
curStr.pop_back();
visited[i] = false;
}
return false;
}
int main() {
string s;
cin >> s;
for (char c : s) {
cnt[c - 'a']++;
}
int k = 0;
for (int i = 0; i < 26; i++) {
if (cnt[i] % 2 == 1) {
k++;
}
mp[char(i + 'a')] = cnt[i];
}
if (k > 1) {
cout << "Impossible" << endl;
return 0;
}
int n = s.size() / 2;
string curStr;
if (k == 1) {
for (auto [c, t] : mp) {
if (t % 2 == 1) {
curStr.push_back(c);
t--;
break;
}
}
n--;
}
dfs(0, n, s, curStr);
if (curStr.size() == s.size() / 2) {
cout << 1 << endl;
cout << curStr;
if (k == 1) {
cout << curStr[0];
}
reverse(curStr.begin(), curStr.end());
cout << curStr << endl;
} else {
cout << "Impossible" << endl;
}
return 0;
}
思路:
本题解使用深度优先搜索(DFS)来寻找构成回文串的子串。具体而言,对于每个长度为 $n$ 的字符串,我们先统计每个字符出现的次数,并判断是否存在奇数个数的字符。如果存在多于一个的奇数个数的字符,则无法组成回文串,直接输出 Impossible。否则,我们可以通过递归调用 dfs 函数来寻找回文串。具体而言,在递归调用 dfs 函数时,我们枚举所有未被访问的字符,如果该字符是奇数个数的字符,并且已经访问过了该字符的前一个字符,则跳过该字符,否则我们选择该字符,继续递归调用 dfs 函数。
- 文章:回文数的判断与实现(C++) 中也许有你想要的答案,请看下吧