关于#LSTM#的问题,如何解决?
毕业论文,物流方向的,想做一个LSTM的预测,在b站上找了个教程,训练出的结果绘图符合预期,但是需要预测的目标数据范围从22.2-23.6变成了0-120。
因为之前从未接触过python和机器学习,所以就把全部代码放出来:
这里得出的RMSE也不符合预期,找正常数据来说跨度不可能这么大
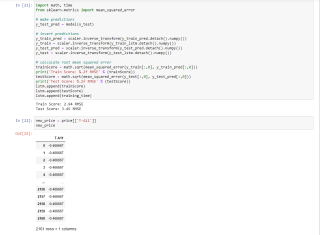
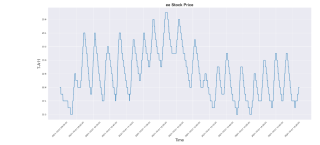
在这里的结果中,y轴数据范围变成了0-120,但是图形符合预期
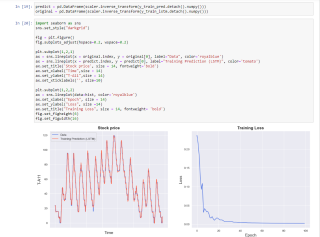
在最后的汇总图里面,y轴数据仍然和原来的不一样,图形仍符合预期
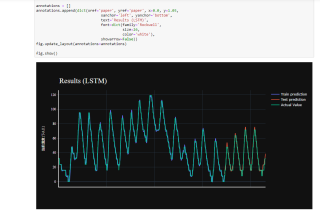
训练过程和代码如上,使用的是jupyter,求知道怎么让训练结果的y轴和实际数据相同,且RMSE符合预期,谢谢各位。
jupyter上复制下来的代码在这下面:
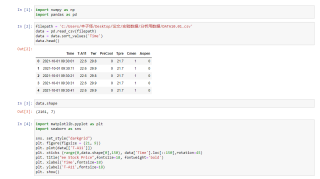
# In[1]:
import numpy as np
import pandas as pd
# In[2]:
filepath = 'C:/Users/本子怪/Desktop/论文/实验数据/分析用数据/DATA10.01.csv'
data = pd.read_csv(filepath)
data = data.sort_values('Time')
data.head()
# In[3]:
data.shape
# In[4]:
import matplotlib.pyplot as plt
import seaborn as sns
sns. set_style("darkgrid")
plt. figure(figsize = (21, 9))
plt. plot(data[['T-A11']])
plt. xticks (range(0,data.shape[0],150), data['Time'].loc[::150],rotation=45)
plt. title("ee Stock Price",fontsize=18, fontweight='bold')
plt. xlabel('Time',fontsize=18)
plt. ylabel('T-A11',fontsize=18)
plt. show()
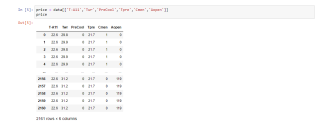
# In[5]:
price = data[['T-A11','Twr','PreCool','Tpre','Cmen','Aopen']]
price
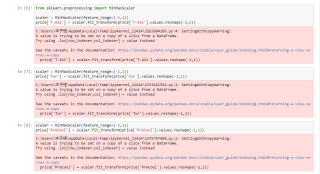
# In[6]:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1,1))
price['T-A11'] = scaler.fit_transform(price['T-A11'].values.reshape(-1,1))
# In[7]:
price['Twr'] = scaler.fit_transform(price['Twr'].values.reshape(-1,1))
# In[8]:
price['PreCool'] = scaler.fit_transform(price['PreCool'].values.reshape(-1,1))
# In[9]:
price['Tpre'] = scaler.fit_transform(price['Tpre'].values.reshape(-1,1))
# In[10]:
price['Cmen'] = scaler.fit_transform(price['Cmen'].values.reshape(-1,1))
# In[11]:
price['Aopen'] = scaler.fit_transform(price['Aopen'].values.reshape(-1,1))
price
# In[12]:
def split_data(stock, lookback):
data_raw = stock.to_numpy()
data = []
# you can free play (seqlength)
for index in range(len(data_raw) - lookback):
data.append(data_raw[index: index + lookback])
data = np.array(data);
test_set_size = int(np.round(0.2 * data.shape[0]))
train_set_size = data.shape[0] - (test_set_size)
x_train = data[:train_set_size,:-1,:]
y_train = data[:train_set_size,-1,0:1]
x_test = data[train_set_size:,:-1,:]
y_test = data[train_set_size:,-1,0:1]
return [x_train, y_train, x_test, y_test]
# In[13]:
lookback = 20
x_train, y_train, x_test, y_test = split_data(price, lookback)
print('x_train.shape = ',x_train.shape)
print('y_train.shape = ',y_train.shape)
print('x_test.shape = ',x_test.shape)
print('y_test.shape = ',y_test.shape)
# In[14]:
import torch
import torch.nn as nn
x_train = torch.from_numpy (x_train).type(torch.Tensor)
x_test = torch.from_numpy(x_test).type(torch.Tensor)
y_train_lstm = torch.from_numpy(y_train).type(torch.Tensor)
y_test_lstm = torch.from_numpy(y_test).type(torch.Tensor)
y_train_gru = torch.from_numpy(y_train).type(torch.Tensor)
y_test_gru = torch.from_numpy(y_test).type(torch.Tensor)
# In[15]:
input_dim = 6
hidden_dim = 32
num_layers = 2
output_dim = 1
num_epochs = 100
# In[16]:
class LSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
super(LSTM, self). __init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
out, (hn,cn)= self.lstm(x, (h0.detach(), c0.detach()))
out = self.fc(out[:,-1, :])
return out
# In[17]:
model = LSTM(input_dim=input_dim, hidden_dim = hidden_dim, num_layers = num_layers, output_dim = output_dim)
criterion = torch.nn.MSELoss()
optimiser = torch.optim.Adam(model.parameters(),lr=0.01)
# In[18]:
import time
hist = np.zeros(num_epochs)
start_time = time.time()
lstm = []
for t in range(num_epochs):
y_train_pred = model(x_train)
loss = criterion(y_train_pred, y_train_lstm)
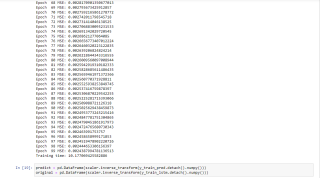
print("Epoch ", t,"MSE:", loss.item())
hist[t] = loss.item()
optimiser.zero_grad()
loss.backward()
optimiser.step()
training_time = time.time()-start_time
print("Training time: {}".format(training_time))
# In[19]:
predict = pd.DataFrame(scaler.inverse_transform(y_train_pred.detach().numpy()))
original = pd.DataFrame(scaler.inverse_transform(y_train_lstm.detach().numpy()))
# In[20]:
import seaborn as sns
sns.set_style("darkgrid")
fig = plt.figure()
fig.subplots_adjust(hspace=0.2, wspace=0.2)
plt.subplot(1,2,1)
ax = sns.lineplot(x = original.index, y = original[0], label="Data", color='royalblue')
ax = sns.lineplot(x = predict.index, y = predict[0], label="Training Prediction (LSTM)", color='tomato')
ax.set_title('Stock price', size = 14, fontweight='bold')
ax.set_xlabel("Time",size = 14)
ax.set_ylabel("T-A11",size = 14)
ax.set_xticklabels('', size=10)
#手动更改标签以及刻度
#ax.set_yticklabels([22.2,22.4,22.6,22.8,23.0,23.2,23.4,23.6])
plt.subplot(1,2,2)
ax = sns.lineplot(data=hist, color='royalblue')
ax.set_xlabel("Epoch", size = 14)
ax.set_ylabel("Loss", size =14)
ax.set_title("Training Loss", size = 14, fontweight= 'bold')
fig.set_figheight(6)
fig.set_figwidth(16)
# In[21]:
import math, time
from sklearn.metrics import mean_squared_error
# make predictions
y_test_pred = model(x_test)
# invert predictions
y_train_pred = scaler.inverse_transform(y_train_pred.detach().numpy())
y_train = scaler.inverse_transform(y_train_lstm.detach().numpy())
y_test_pred = scaler.inverse_transform(y_test_pred.detach().numpy())
y_test = scaler.inverse_transform(y_test_lstm.detach().numpy())
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(y_train[:,0], y_train_pred[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(y_test[:,0], y_test_pred[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
lstm.append(trainScore)
lstm.append(testScore)
lstm.append(training_time)
# In[22]:
new_price = price[['T-A11']]
new_price
# In[23]:
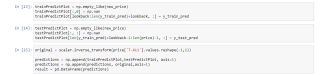
trainPredictPlot = np.empty_like(new_price)
trainPredictPlot[:,0] = np.nan
trainPredictPlot[lookback:len(y_train_pred)+lookback, :] = y_train_pred
# In[24]:
testPredictPlot = np.empty_like(new_price)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(y_train_pred)+lookback-1:len(price)-1, :] = y_test_pred
# In[25]:
original = scaler.inverse_transform(price['T-A11'].values.reshape(-1,1))
predictions = np.append(trainPredictPlot,testPredictPlot, axis=1)
predictions = np.append(predictions, original,axis=1)
result = pd.DataFrame(predictions)
# In[26]:
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(go.Scatter(x=result.index, y=result[0],
mode='lines',
name='Train prediction')))
fig.add_trace(go.Scatter(x=result.index, y=result[1],
mode='lines',
name='Test prediction'))
fig.add_trace(go.Scatter(go.Scatter(x=result.index, y=result[2],
mode='lines',
name='Actual Value')))
fig.update_layout(
xaxis=dict(
showline=True,
showgrid=True,
showticklabels=False,
linecolor='white',
linewidth=2
),
yaxis=dict(
title_text='当前温度 (T-A11)',
titlefont=dict(
family='Rockwell',
size=12,
color='white',
),
showline=True,
showgrid=True,
showticklabels=True,
linecolor='white',
linewidth=2,
ticks='outside',
tickfont=dict(
family='Rockwell',
size=12,
color='white',
),
),
showlegend=True,
template ='plotly_dark'
)
annotations = []
annotations.append(dict(xref='paper', yref='paper', x=0.0, y=1.05,
xanchor='left', yanchor='bottom',
text='Results (LSTM)',
font=dict(family='Rockwell',
size=26,
color='white'),
showarrow=False))
fig.update_layout(annotations=annotations)
fig.show()
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
根据您提供的代码,可以发现训练出来的 LSTM 模型在预测时的表现并不理想。在分析时需要注意以下几点:
- 数据归一化
由于 LSTM 模型的特点,输入数据需要进行归一化。在您的代码中已经使用了 sklearn 的 MinMaxScaler 进行数据归一化,这是正确的。
- 数据集生成方式
在您的代码中,数据集是通过将连续的若干行数据合并为一个训练/测试数据,这种方式虽然能够将序列信息传给模型,但是容易造成信息丢失。而在实际物流预测的应用场景中,时间序列的填充方式可能不太合适。因此,建议您使用一些其他的方法,例如滑动窗口法等,来生成数据集。
- 模型参数的选择
您的代码中选择了 2 层 LSTM,hidden state 的维度,hidden_dim 是 32,学习率 lr 是 0.01。这些参数的选择可能不太合适。建议您通过一定的试验,调整模型参数,比如可以尝试调整 LSTM 层数、隐藏节点数等参数,从而得到更好的模型。此外,建议您在模型训练过程中使用交叉验证等技术,对模型进行评估和调优。
- 模型训练过程中的问题
在您的代码中,训练过程中使用了 y_train_lstm 进行训练和误差计算,但是未调用 model.eval() 方法以使用 y_test_lstm 进行测试。此外,代码中使用了 torch.nn.MSELoss() 作为损失函数,但是可以尝试使用其他的损失函数来进行训练,比如说 Huber Loss,MAE 等,从而提高模型的鲁棒性。
综上所述,建议您参考一些 LSTM 预测模型的开源项目,尝试使用其他的数据集,并调整模型参数,从而得到更好的预测结果。以下是一个 LSTM 预测模型的示例代码,仅供参考:
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
class LSTMModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = torch.nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc = torch.nn.Linear(in_features=hidden_size, out_features=output_size)
def forward(self, x):
h_0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c_0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
_, (h, _) = self.lstm(x, (h_0, c_0))
out = self.fc(h[-1, :, :])
return out
class Trainer:
def __init__(self, model, loss_fn, optimizer):
self.model = model
self.loss_fn = loss_fn
self.optimizer = optimizer
def train(self, x, y):
self.model.train()
self.optimizer.zero_grad()
out = self.model(x)
loss = self.loss_fn(out.view(-1), y.view(-1))
loss.backward()
self.optimizer.step()
return loss.item()
def validate(self, x, y):
self.model.eval()
with torch.no_grad():
out = self.model(x)
loss = self.loss_fn(out.view(-1), y.view(-1))
return loss.item()
def predict(self, x):
self.model.eval()
with torch.no_grad():
out = self.model(x)
return out.view(-1)
def save(self, epoch, model_path):
torch.save({
'epoch': epoch,
'state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
}, model_path)
def load(self, model_path):
checkpoint = torch.load(model_path)
self.model.load_state_dict(checkpoint['state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
return epoch
def preprocess_data(data, train_ratio):
"""
:param data: pandas.DataFrame, raw data with column 'T-A11'
:param train_ratio: float, ratio of training set to validation set
:return: tuple, (train_data, val_data), each of which contain numpy.ndarray of shape (num_data, num_features)
"""
scaler = MinMaxScaler()
data_norm = scaler.fit_transform(data)
train_size = int(len(data_norm) * train_ratio)
train_data = data_norm[:train_size, :]
val_data = data_norm[train_size:, :]
return train_data, val_data
def create_dataset(data, lookback):
"""
:param data: numpy.ndarray of shape (num_data, num_features)
:param lookback: int, number of past time steps to use for next time step prediction
:return: tuple, (x, y) numpy.ndarray of shapes (num_samples, lookback, num_features) and (num_samples, 1)
"""
x, y = [], []
for i in range(lookback, len(data)):
x_ = data[i-lookback:i, :]
y_ = data[i, 0] # predict only first column (T-A11)
x.append(x_)
y.append(y_)
return np.array(x), np.array(y).reshape(-1, 1)
def train_model(train_data, val_data, lookback, hidden_size, num_layers, num_epochs, lr):
train_x, train_y = create_dataset(train_data, lookback)
val_x, val_y = create_dataset(val_data, lookback)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LSTMModel(input_size=train_x.shape[-1], hidden_size=hidden_size, num_layers=num_layers,
output_size=train_y.shape[-1]).to(device)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-5)
trainer = Trainer(model, loss_fn, optimizer)
train_losses, val_losses = [], []
如果我的回答解决了您的问题,请采纳!
代码不要贴图片,不方便复制,如果有代码,可能回答更准确
参考GPT和自己的思路:关于LSTM的问题,我可以提供以下建议:
1 数据预处理:可能需要对输入数据进行归一化或标准化处理,以确保数据范围在可接受的范围内。你可以尝试将数据重新调整到22.2-23.6范围内,再重新训练模型。
2 超参数调整:尝试调整LSTM模型的超参数,例如学习率、epoch数、batch size等,以获得更好的性能和更符合预期的结果。你可以通过Grid Search或Random Search等方法来寻找最优超参数组合。
3 模型调整:尝试使用不同的LSTM结构或激活函数,或添加其他类型的层,以改善模型性能。你可以尝试使用其他常用的LSTM变体,如GRU、BiLSTM等。
4 数据集调整:如果你的数据集较小,可以尝试使用数据增强技术来扩展数据集。此外,还可以考虑收集更多的数据,以获得更准确的预测结果。
5 代码检查:最后,你可以检查一下代码是否正确,是否存在错误或缺陷。你可以使用调试工具或日志来诊断问题并进行修复。
希望以上建议能够帮助你解决问题。
根据报错信息来看,还是类型的问题
参考GPT和自己的思路,您的问题似乎是有关于数据归一化的问题。神经网络模型的训练数据应该在一个相似的数值范围内,这有助于模型更快地收敛并减少误差。在使用LSTM模型时,数据归一化也是一个必要的步骤。在您的情况下,您的训练数据范围从22.2-23.6变成了0-120,这意味着您的数据需要进行归一化。
一种常用的方法是将数据缩放到[0,1]的范围内,方法是将每个值减去最小值,然后除以最大值和最小值之间的范围。
具体来说,您可以按照以下步骤进行数据归一化:
1.计算数据集的最小值和最大值。
2.对于每个数据点,将其减去最小值并除以最大值和最小值之间的范围。
3.在模型训练之前,使用相同的缩放器将测试数据进行归一化。
代码示例:
import numpy as np
# 假设您的训练数据在train_data中
# 计算数据集的最小值和最大值
data_min = np.min(train_data)
data_max = np.max(train_data)
# 将数据归一化
normalized_train_data = (train_data - data_min) / (data_max - data_min)
# 在模型训练之前,使用相同的缩放器将测试数据进行归一化
normalized_test_data = (test_data - data_min) / (data_max - data_min)
注意:在对测试数据进行归一化时,使用的缩放器应该是从训练数据中计算出的最小值和最大值。这样可以保证测试数据与训练数据的归一化方式是一致的。
此外,您还可以计算模型的均方根误差(RMSE)来评估模型的性能。均方根误差是预测值和实际值之间差异的标准度量。较小的RMSE值表示模型的性能更好。
代码示例:
from sklearn.metrics import mean_squared_error
# 假设您的模型预测结果在y_pred中,实际值在y_true中
# 计算均方根误差
rmse = mean_squared_error(y_true, y_pred, squared=False)
希望这些信息能对您有所帮助。
- 这篇文章讲的很详细,请看:LSTM为什么能够解决梯度消失以及LSTM调参