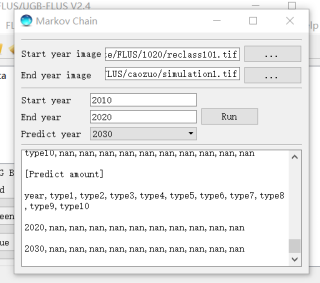
土地利用flus模型马尔科夫(markov)预测结果是nan
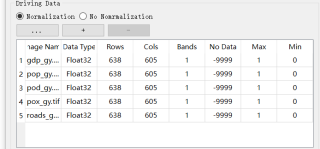
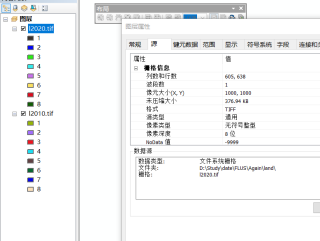
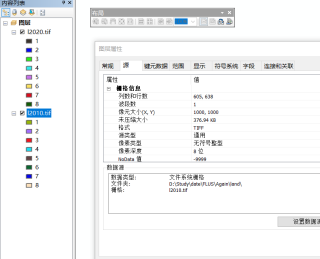
我想用2010年和2020年土地利用数据,预测2030年数据。其中土地利用数据和驱动因子数据的行列数、像元大小、投影坐标都是一致的。土地利用数据重分类序号1-8,驱动因子也都进行了归一化,kappa系数为0.89。
但在用markov链预测时显示的结果都是nan,这该怎么解决啊。
数据信息
参考GPT和自己的思路,在土地利用Flus模型中,Markov链是用于预测未来时间步的土地利用变化的重要方法。在您的情况下,如果Markov链预测的结果为nan,则表示该模型无法计算出预测结果。
有几种可能导致Markov链预测结果为nan,以下是一些可能的原因:
1.数据输入格式有误:确保您输入的数据格式正确,包括数据类型和数据范围。检查一下输入数据的缺失值情况,确保没有nan值出现。
2.数据的一致性问题:请确保您的驱动因子数据和土地利用数据的投影坐标系一致,像元大小一致,以及行列数一致。
3.数据的质量问题:如果数据质量较差,则可能会导致预测结果为nan。确保您的输入数据已经进行了正确的预处理和清理,例如去除离群值和异常值等。
4.模型参数问题:如果模型参数设置不正确,也可能导致预测结果为nan。请检查模型参数设置是否正确。
建议您逐步排除这些可能的原因,并逐步测试和调整模型参数和输入数据,直到找到问题的根源。另外,也可以考虑使用其他预测方法来检查您的输入数据和模型是否存在问题。
nan说明数字无效,或者是极大的值,肯定是程序错了。
参考GPT和自己的思路:出现NaN结果可能有多种原因,以下是几种可能的情况和对应的解决方法:
1 数据格式问题:请确保你的输入数据格式正确,包括数据类型和数据范围。比如,是否有空值或者无穷大的数据。可以使用MATLAB等软件对数据进行查看和处理。
2 算法问题:请检查你使用的算法是否适合你的数据。比如,markov模型需要的前提是状态转移概率是稳定的,否则预测结果可能会很差。你可以尝试使用其他模型或者调整参数来改进结果。
3 计算问题:请确保你的计算过程正确,并且没有出现数据丢失或计算错误。比如,你可以检查每一步的计算结果,看看是否出现问题。
4 数据量问题:请确保你的数据量足够,否则可能会出现过拟合或欠拟合的情况。你可以尝试增加数据量或者调整数据采样方法。
总的来说,需要逐一排查上述可能的原因,并根据具体情况进行相应的处理和调整。
参考GPT和自己的思路:
在使用markov链预测时出现NaN的情况可能是由于数据中存在缺失值或空值等无效数据导致的。请检查你的数据中是否有NaN值或其他无效数据,需要将它们进行处理或剔除,确保数据的完整性和准确性,以保证预测结果的正确性。如果数据已经处理干净了,可以尝试调整Markov模型的参数,例如调整阈值等,以检查是否可以解决预测出现NaN值的问题。希望能对你有所帮助!
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
首先,需要了解马尔科夫链预测模型的基本思路及其适用条件。
马尔科夫链预测模型是基于时间序列的预测模型,它假设未来状态只取决于当前状态,而与过去状态无关。这种模型适用于满足马尔科夫链假设的时间序列,即未来状态只与当前状态有关,并且同一状态在不同时间的概率分布不变。
在预测土地利用变化时,我们需要选定一定时间段内的土地利用数据,将其视为当前状态,并利用历史数据计算状态转移概率矩阵,进而预测未来状态。
但是,在现实应用中,马尔科夫链预测模型也存在很多限制和不足,比如需要满足稳定性、各状态转移概率存在、时间不变性等条件。
具体到你的问题中,可能存在以下几个方面的原因:
数据处理问题:可能存在部分数据缺失、异常值、空值等。需要在进行数据预处理和清洗时尽可能减少这些问题。
数据连续性问题:马尔科夫链预测模型假设同一状态在不同时间的概率分布不变,即各状态之间具有较大连续性。如果时间序列中存在较大的跳跃或变化,可能会导致预测结果不准确。
状态数量问题:模型存在的状态数量需要尽可能丰富,但也需要避免状态数过多导致矩阵计算出现问题。在确定状态数时需要结合实际情况进行权衡。
在解决这些问题的同时,还需要考虑模型参数设置、模型评价、模型拟合等问题。
下面是一份简单的python代码,用于基于马尔科夫链模型预测土地利用变化:
import numpy as np
from numpy.linalg import matrix_power
# 定义状态转移矩阵P,如下所示:
P = np.array(
[
[0.4, 0.3, 0.1, 0.1, 0.0, 0.0, 0.1, 0.0],
[0.1, 0.5, 0.2, 0.1, 0.0, 0.0, 0.1, 0.0],
[0.0, 0.4, 0.4, 0.1, 0.0, 0.0, 0.1, 0.0],
[0.0, 0.3, 0.2, 0.3, 0.0, 0.0, 0.2, 0.0],
[0.0, 0.0, 0.1, 0.1, 0.8, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.1, 0.0, 0.9, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.2, 0.0, 0.2, 0.0, 0.6, 0.0],
[0.0, 0.0, 0.1, 0.0, 0.0, 0.0, 0.1, 0.8]
]
)
# 给出初始状态的概率分布v,如下所示:
v = np.array([0.2, 0.2, 0.2, 0.2, 0.1, 0.0, 0.1, 0.0])
# 定义马尔科夫链模型的预测步数
n = 3
# 通过矩阵的乘方计算预测结果
predicted_state = matrix_power(P, n).dot(v)
print(predicted_state)
在这份代码中,我们假设有8种不同的土地利用类型,并给出了状态转移矩阵P和初始状态分布v。利用这两个参数和预测步数n,可以简单地计算出未来状态的概率分布,得到预测结果。
需要注意的是,在实际应用中,模型参数的确定以及模型评价的方法需要结合实际情况进行综合考虑。以上代码只是展示了马尔科夫链模型的基本思路,实际上需要依据实际的数据特征和需求进行合理的设置和调整。
如果我的回答解决了您的问题,请采纳!