网页内容解析,python
对爬取到的网页信息不会解析
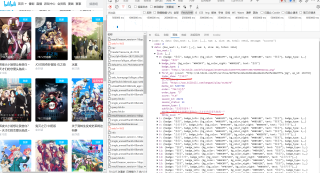
代码已经爬取,想要解析出这title和index_show这两个信息,最近学了beautifulsoup,但是这段代码里好像没有那样可以检索的标签,自己搜索了好像是使用json,但是没有找到清晰的解答,求指路,感谢
这都直接返回json信息了。
看别的视频找到了可行的方法,分享在评论区
response = requests.get(f"url",headers=headers)
html = response.json()
for num in range(0,20,1):
bangumi_title = html['data']['list'][num]['title']
print(bangumi_title)