python中pandas库生成二维数组的使用
dates = pd.date_range(start='20191101', end='20191124', freq='D')
a1 = pd.DataFrame(np.random.randn(24, 4), index=dates, columns=list('ABCD'))
a2 = pd.DataFrame(np.random.rand(24, 4))
(np.random.randn(24, 4)和(np.random.rand(24, 4)) 中的randn与rand有什么区别
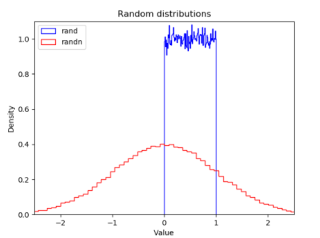
rand是随机生成值在0-1之间的函数;
randn是随机生成均值为0,方差为1的正态分布上的数值。
看这个图体会下区别:
有帮助的话,请点采纳该答案~
np.random.randn(24, 4)和np.random.rand(24, 4)都是生成24行4列的随机数组,不同之处在于它们生成随机数的方式不同。
np.random.randn(24, 4)生成的是标准正态分布(均值为0,标准差为1)的随机数组,即生成的每个数都是从标准正态分布中随机抽取的。而np.random.rand(24, 4)生成的是在[0,1)区间内均匀分布的随机数组,即生成的每个数都是从[0,1)区间内随机抽取的。
因此,np.random.randn()生成的随机数组更容易产生极端值(如非常大或非常小的值),而np.random.rand()生成的随机数组则更加平均。
答案来自 我点评开发社区 https://www.wodianping.com/
该回答引用GPTᴼᴾᴱᴺᴬᴵ
在上述代码中,使用了NumPy和Pandas库,生成了两个二维数组a1和a2。其中,np.random.randn(24, 4)和np.random.rand(24, 4)都是NumPy库中的随机数生成函数,它们的区别如下:
np.random.randn(24, 4)生成的是一个24行4列的二维数组,数组中的每个元素都是从标准正态分布中随机采样得到的。
np.random.rand(24, 4)生成的是一个24行4列的二维数组,数组中的每个元素都是从[0,1)的均匀分布中随机采样得到的。
因此,二者的区别在于所采样的分布不同。在实际应用中,根据需要选择合适的分布进行随机数生成。在上述代码中,np.random.randn(24, 4)和np.random.rand(24, 4)分别用来生成随机数,以填充DataFrame的值,从而创建一个带有索引和列名的二维数组。
- 这篇文章:Python之pandas(二) 也许能够解决你的问题,你可以看下