BP神经网络预测问题
BP神经网络训练集中,前一半误差比较小,后一半误差比较大,请问是什么原因,是过拟合吗?
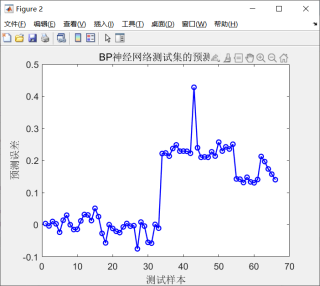
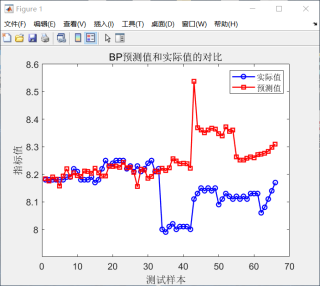
该回答引用GPTᴼᴾᴱᴺᴬᴵ
在BP神经网络中,训练误差过小或过大都可能是过拟合的表现,但这并不是唯一的原因。在这种情况下,可能存在以下几种情况:
·
数据分布不均:前一半数据和后一半数据分布不同,导致模型对于前一半数据表现得更好,而对于后一半数据表现不佳。
·
数据集不足:如果数据集太小,可能会导致模型无法很好地泛化,特别是在后一半数据集中,因为它们可能包含比前一半数据集中更多的复杂模式和变化。
·
模型过拟合:如果模型过于复杂或训练次数过多,则可能导致模型在前一半数据集上过拟合,而在后一半数据集上表现不佳。
·
因此,在遇到这种情况时,应该进一步探究原因,以确定如何进一步改进模型。例如,可以尝试更好地平衡数据集,增加更多的训练数据或者减少模型的复杂度等方法来避免过拟合等问题。
过拟合指的是模型在训练集上表现得很好,但是在测试集上表现不佳的情况。在BP神经网络中,过拟合的原因可能是模型的复杂度过高,导致模型过度适应了训练集的特征,从而无法很好地泛化到测试集上。
解决过拟合的方法包括:
减少模型的复杂度:可以通过减少神经网络的层数或神经元的数量来减少模型的复杂度。
增加训练数据:可以通过增加训练数据的数量来避免过拟合。
正则化:可以通过添加L1或L2正则化项来限制权重的大小,从而减少模型的复杂度。
Dropout:可以在神经网络的训练过程中随机丢弃一些神经元,从而减少神经网络的复杂度。
需要根据实际情况进行调整,找到合适的方法来解决过拟合问题。
引用gpt
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7771912
- 这篇博客你也可以参考下:BP神经网络解决相关问题
- 您还可以看一下 nan老师的[多特征预测]基于BP神经网络多特征电力负荷预测课程中的 4.1 BP神经网络如何进行多特征用电负荷预测小节, 巩固相关知识点