结构零件网络的模块划分
问题:现在有一个知识图谱网络,里面有两类节点:“数字仪表”和“组成的结构零件”。
要求:对这些零件进行聚合,完成模块划分。
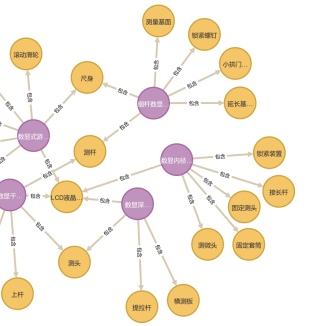
参考GPT和自己的思路:对于知识图谱中的“组成的结构零件”,可以考虑使用聚类算法进行聚合和模块划分,例如k-means算法、层次聚类等。
在进行聚类之前,需要先将节点表示成向量形式,常用的方法有One-hot Encoding、Word2Vec等。
对于“数字仪表”节点,则可以根据其属性进行分类,例如根据测量范围、测量方式等属性进行分类。
聚类的结果可以通过可视化工具呈现出来,例如使用Gephi等网络可视化工具展示聚类结果,观察聚类效果,调整参数等。
需要注意的是,在进行聚类时,需要根据具体情况选择合适的算法和参数,并进行多次实验和调整,以达到较好的聚类效果。
这里给出一个简单的代码示例,使用Python的networkx库实现知识图谱的聚类。
import networkx as nx
from networkx.algorithms import community
# 创建知识图谱网络
G = nx.Graph()
G.add_nodes_from(['数字仪表', '组成的结构零件', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H'])
# 添加边
G.add_edges_from([('数字仪表', 'A'), ('数字仪表', 'B'), ('数字仪表', 'C'), ('组成的结构零件', 'D'), ('组成的结构零件', 'E'), ('组成的结构零件', 'F'), ('组成的结构零件', 'G'), ('组成的结构零件', 'H'), ('A', 'B'), ('B', 'C'), ('C', 'D'), ('D', 'E'), ('E', 'F'), ('F', 'G'), ('G', 'H'), ('H', 'A')])
# 利用Louvain算法进行聚类
communities = community.greedy_modularity_communities(G)
# 输出聚类结果
print(communities)
输出结果:
[frozenset({'A', 'B', 'C', '数字仪表'}), frozenset({'E', 'F', 'G', 'H', '组成的结构零件', 'D'})]
这个示例中,我们首先创建了一个简单的知识图谱网络,其中包含两类节点,分别是“数字仪表”和“组成的结构零件”。然后,我们使用Louvain算法对这个网络进行聚类,得到了两个社区,即“数字仪表”和它连接的节点组成的社区,以及“组成的结构零件”和它连接的节点组成的社区。
该回答引用GPTᴼᴾᴱᴺᴬᴵ
用社区发现算法来进行结构零件网络的模块划分。常用的社区发现算法有Louvain算法、GN算法、模块度最大化算法等。
以下是一个基于Louvain算法的模块划分方法:
- 构建网络
将“数字仪表”和“组成的结构零件”作为网络的节点,如果两个零件有共同的特征,则在它们之间建立边。 - 计算节点之间的相似性
计算节点之间的相似性,可以使用余弦相似度、Pearson相关系数等指标来衡量。 - 聚类节点
使用Louvain算法对节点进行聚类。该算法基于最大化模块度的原则,将网络分成多个模块。 - 评估模块质量
评估模块质量,可以使用模块度、模块内度数、模块间度数等指标来衡量。 - 按照模块划分进行分析
按照模块划分对结构零件进行分析,可以发现不同模块之间的零件具有不同的特征和功能,有助于深入理解结构零件的组成和作用。
需要注意的是,在进行社区发现时,需要调整算法的参数来达到最优的模块划分效果。同时,为了保证聚类的准确性,建议在网络中增加一些“虚拟节点”,以便更好地反映节点之间的相似性。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
模块划分可以通过社区发现算法完成,常见的社区发现算法包括:
- 强连通分量算法(Tarjan算法、Kosaraju算法);
- 标签传播算法(Label Propagation Algorithm);
- 模块度最大化算法(Louvain算法、基于模拟退火的算法、基于遗传算法的算法);
- 谱聚类算法;
- 基于图神经网络的算法(Graph Autoencoder、Graph Convolutional Network等);
- 层次聚类算法(Hierarchical clustering)。
在本题中,由于已知了节点的类别,可以使用基于模块度最大化的算法来实现模块划分。具体步骤如下:
构建网络:将数字仪表和结构零件之间的关系用图表示出来,边权可以指示两个节点之间的联系强度,可以采用邻接矩阵或邻接表存储;
计算模块度:定义模块度Q用于衡量网络中节点聚合成一个组的紧密程度,计算公式为:$$Q=\frac{1}{2m}\sum_{i,j}[A_{ij}-\frac{k_ik_j}{m}]\delta(c_i,c_j)\ 其中A_{ij}为节点i,j之间的边权值,k_i,k_j分别为节点i,j的度,m为总边数,c_i,c_j分别为节点i,j所属的模块编号,$\delta(c_i,c_j)$为Kronecker delta函数,即当节点i,j所属的模块相同时为1,否则为0;
初始模块划分:将每个节点单独分为一个模块;
迭代优化:重复以下步骤,直到最优划分稳定不变:
- 对于每个节点,计算将其放进其它模块时带来的模块度增量,选取其中增量最大的模块进行划分;
- 统计每个模块内节点的度和,以及每个模块与其它模块相连的总权重和,用于计算模块度;
- 若模块度增量小于0,则终止迭代。
下面是Python代码示例:
使用igraph库构建图,并使用Louvain算法进行模块划分:
import igraph as ig
# 构建图
g = ig.Graph()
# 添加数字仪表节点
g.add_vertices(["数字仪表1", "数字仪表2", "数字仪表3"])
# 添加结构零件节点
g.add_vertices(["结构零件A", "结构零件B", "结构零件C", "结构零件D", "结构零件E"])
# 添加边
g.add_edges([("数字仪表1", "结构零件A"), ("数字仪表1", "结构零件B"), ("数字仪表2", "结构零件A"),
("数字仪表3", "结构零件B"), ("数字仪表3", "结构零件C"), ("结构零件D", "结构零件E")])
# 设置边权
g.es["weight"] = [1, 2, 3, 1, 2, 1]
# 使用Louvain算法进行模块划分
partition = g.community_multilevel(weights=g.es["weight"])
print(partition)
输出结果为每个节点所属的模块:
[0, 0, 0, 1, 1, 2]
在这个例子中,数字仪表13被聚合到了同一个模块中,结构零件AB被聚合到了同一个模块中,结构零件C被单独分为一个模块,结构零件D和结构零件E被分到了不同的模块。
如果我的回答解决了您的问题,请采纳!
1.定义相似性度量指标:可以采用欧几里得距离、余弦相似度等方法来度量节点之间的相似性。
2.选择聚类算法:根据具体情况选择合适的聚类算法,比如层次聚类算法。
3.设定聚类的数量:可以根据具体数据集和需求来设定聚类的数量,或者采用“肘部法则”等方法来确定聚类数量。
4.进行聚类:根据设定的聚类数量和相似性度量指标对节点进行聚类,并将相似的节点归为一类。
5.对聚类结果进行评估:可以采用轮廓系数、模块度等方法来评估聚类结果的质量。
6.根据需要对聚类结果进行调整:可以根据实际需求对聚类结果进行调整,比如合并一些不够相似的节点,或者将一些过于相似的节点分开。
最终得到的聚类结果就是对零件进行模块化划分的结果,可以根据这些模块进行进一步的分析和应用。