某公司的数据专员面试题
https://zb6okqgl47.feishu.cn/docx/doxcnRuV1CNpKZ5jmcNFIwa34fc
这是一道数据专员的题目,个人觉得难度有点大,向各位赐教,谢谢
备注:虽然说语言不限,但是请各位有python 或者mysql(我只会这两个)
1、涉及SQL(使用 MySQL8 数据库):
WITH t0 AS ( -- 提取有效时间范围内的有效数据及日期转月份,并去重(一个月一个用户只计算一次)
SELECT DISTINCT user_id, date_add( order_date, INTERVAL -DAY( order_date ) + 1 day ) mon FROM t_order WHERE order_status = '交易成功' AND order_date >= date'2021-01-01' AND order_date < date'2021-10-01' )
, t1 AS ( -- 人员按月份排序及提取第一次购买月份
SELECT user_id, mon, ROW_NUMBER( ) OVER( PARTITION BY user_id ORDER BY mon ) rn, FIRST_VALUE( mon ) OVER( PARTITION BY user_id ORDER BY mon ) mm FROM t0 )
, t2 AS ( -- 计算每个人员的各月份购买分布
SELECT mm, user_id, rn
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 1 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 1 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M1
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 2 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 2 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M2
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 3 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 3 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M3
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 4 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 4 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M4
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 5 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 5 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M5
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 6 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 6 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M6
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 7 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 7 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M7
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 8 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 8 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M8
, ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 9 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 9 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M9
-- , ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 10 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 10 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M10
-- , ( CASE WHEN rn > 1 AND mon = date_add( mm, INTERVAL 11 MONTH ) THEN 1 WHEN date_add( mm, INTERVAL 11 MONTH ) >= date'2021-10-01' THEN NULL ELSE 0 END ) M11
FROM t1 )
, t3 AS ( -- 统计各月份购买及回购数量
SELECT mm, sum( CASE WHEN rn = 1 THEN 1 ELSE 0 END ) dy
, sum( m1 ) M1, sum( m2 ) M2, sum( m3 ) M3, sum( m4 ) M4, sum( m5 ) M5, sum( m6 ) M6
, sum( m7 ) M7, sum( m8 ) M8, sum( m9 ) M9-- , sum( m10 ) M10, sum( m11 ) M11
FROM t2
GROUP BY mm )
SELECT mm 首次购买月份, dy 当月新增客户数量
, concat( truncate( M1 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M1
, concat( truncate( M2 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M2
, concat( truncate( M3 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M3
, concat( truncate( M4 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M4
, concat( truncate( M5 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M5
, concat( truncate( M6 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M6
, concat( truncate( M7 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M7
, concat( truncate( M8 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M8
, concat( truncate( M9 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M9
-- , concat( truncate( M10 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M10
-- , concat( truncate( M11 * 100 / ( CASE WHEN dy = 0 THEN 1 ELSE dy END ), 2 ), '%' ) AS M11
FROM t3
ORDER BY mm;
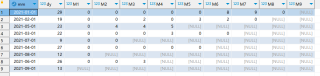
SQL中 t3 子查询的输出:
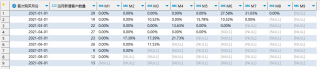
SQL的最终输出:
SQL说明:
①、SQL中的时间范围为:2021-01-01(包含)到 2021-10-01(不包含),程序中为月份范围参数
②、因为需求的时间范围不固定,因此具体SQL也不固定,我故意多输出了一个复购统计月份M9,实际SQL中需要将我屏蔽的M10、M11部分的类似SQL(其实就是所有的 M1 到 M11 部分),根据月份范围计算出需要输出的列的数量(即:[ (结束月份) - (开始月份) - (1) ] 个M列),动态生成具体SQL
2、程序:具体程序就是获取时间范围参数,连接数据库,动态生成上述SQL,执行SQL获取结果并输出,通过word或Excel另存为PDF即可
我试一下,使用python程序实现,不需安装数据库,不需建表,不需导入数据。实现效果:

关键代码:
data = pd.read_excel(r'复购率测试用数据.xlsx', dtype=str)
# 刷选交易成功的数据,不成功的不要
data = data[data['order_status'] == '交易成功']
# print(data)
# 按月统计,将日去掉
data['order_date'] = data['order_date'].apply(lambda x: x[0:7])
# 统计每个月的用户 set去重,表示用户一个月买了多次也只计算一次
df = data.groupby('order_date')[['order_date', 'user_id']].agg(set)
df['new_user_List'] = df['user_id'].apply(newUserList)
print(df['new_user_List'])
# 统计复购人数
df_result_people = pd.DataFrame()
# 统计复购利率
df_result_rate = pd.DataFrame()
for i in range(len(df)):
.................
Python
用pandas读数据,提出交易关闭的数据。
建立一些辅助列,如月份,是否是新客,本月第几次。
df的行列也可以修改为以客户为index,月度为colums。
剩下就是统计操作了
参考GPT和自己的思路,以下是一个示例代码,假设订单数据存储在名为orders的DataFrame中,其中包含列名为order_id、order_date、order_status和user_id:
import pandas as pd
# 将订单日期转换为月份并创建一个新列
orders['order_month'] = pd.to_datetime(orders['order_date']).dt.to_period('M')
# 根据月份和用户ID分组计算复购情况
grouped = orders[orders['order_status'] == '交易成功'].groupby(['order_month', 'user_id'])
repeat_buyers = grouped.filter(lambda x: len(x) > 1)['user_id'].nunique()
total_buyers = grouped['user_id'].nunique().sum()
# 计算复购率
repurchase_rate = repeat_buyers / total_buyers
# 输出结果
print('复购人数:', repeat_buyers)
print('复购率:', round(repurchase_rate * 100, 2), '%')
代码中的第一行将订单日期转换为月份并创建一个名为order_month的新列。第二行根据月份和用户ID分组,过滤出所有有效订单,然后筛选出复购用户并计算其数量。第三行计算所有购买用户的数量,最后根据两个数量计算复购率并输出结果。
import pandas as pd
from datetime import datetime, timedelta
# 读取订单数据,假设数据已经包含了order_status字段
orders = pd.read_csv('orders.csv')
# 确定时间周期的起始日期和结束日期,这里以10月份为例
start_date = datetime(2022, 10, 1)
end_date = datetime(2022, 10, 31)
# 筛选出在时间周期内产生的订单
valid_orders = orders[(orders.order_status == '交易成功') & \
(orders.order_date >= start_date) & \
(orders.order_date <= end_date)]
# 对于每个用户,计算其在时间周期内的复购次数,并记录复购用户数
repeat_users = set()
for user in valid_orders.user_id.unique():
# 获取该用户在时间周期内的订单数据
user_orders = valid_orders[valid_orders.user_id == user].sort_values(by='order_date')
repeat_flag = False
for i in range(1, len(user_orders)):
# 计算相邻订单之间的时间间隔
interval = user_orders.iloc[i].order_date - user_orders.iloc[i-1].order_date
if interval <= timedelta(days=31):
# 如果时间间隔小于等于31天,则认为该订单是复购订单
repeat_flag = True
break
if repeat_flag:
repeat_users.add(user)
# 计算复购率
new_users = len(valid_orders[valid_orders.order_date == start_date].user_id.unique())
repeat_rate = len(repeat_users) / new_users
# 输出结果
print(f'新用户数:{new_users}')
print(f'复购用户数:{len(repeat_users)}')
print(f'复购率:{repeat_rate:.2%}')
需要注意的是,这里假设订单数据已经包含了订单状态(order_status)和订单日期(order_date)字段,如果实际数据中没有这些字段,需要进行相应的处理。此外,代码中的时间周期为10月份,如果需要计算其他时间周期的复购情况,需要相应地修改起始日期和结束日期。