SQL语句根据某一字段相关联多表查询
sql语句多表查询,我是已经通过STCD字段相关联的另一张表的数据的两个字段也显示数据,但想,以下是我已查询到的语句:
select
top 10 r.STCD,sum(r.DRP) as DRP_SUM ,b.STNM,b.STLC
from
RWDB.dbo.ST_PPTN_R r left join RWDB.dbo.ST_STBPRP_B b
on
r.STCD=b.STCD
where
r.TM >= DATEADD(hour,-3,GETDATE())
group by r.STCD,b.STNM,b.STLC
order by sum(r.DRP) desc
就是根据当前时间查询出一小时雨量最大的10个站,并显示相关信息。现在的话需要再加一个特定条件,按流域或县市划分,比如某一流域内一小时雨量最大的10个站。
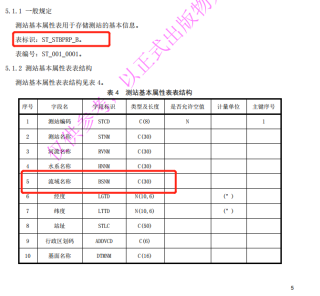
下图是另外这张表的字段和结构:
基于Monster 组和GPT的调写:
如果你想根据流域或县市划分来查询一小时雨量最大的10个站,可以使用以下SQL语句:
-- 根据流域划分查询
select top 10 r.STCD, sum(r.DRP) as DRP_SUM, b.STNM, b.STLC
from RWDB.dbo.ST_PPTN_R r
left join RWDB.dbo.ST_STBPRP_B b on r.STCD = b.STCD
where r.TM >= DATEADD(hour,-3,GETDATE()) and b.BSNM = '某一流域'
group by r.STCD, b.STNM, b.STLC
order by sum(r.DRP) desc
-- 根据县市划分查询
select top 10 r.STCD, sum(r.DRP) as DRP_SUM, b.STNM, b.STLC
from RWDB.dbo.ST_PPTN_R r
left join RWDB.dbo.ST_STBPRP_B b on r.STCD = b.STCD
where r.TM >= DATEADD(hour,-3,GETDATE()) and b.CTZL = '某一县市'
group by r.STCD, b.STNM, b.STLC
order by sum(r.DRP) desc
其中,第一个查询根据流域划分查询,使用了BSNM字段,第二个查询根据县市划分查询,使用了CTZL字段。在查询结果中,DRP_SUM字段表示一小时雨量总和。
该回答引用ChatGPT
找到与流域或县市相关的数据表,确定其表名和字段名。
将查询中的表连接语句改为对应表的连接语句,同时增加连接条件。
在where子句中增加对应条件,以限定查询范围。
select top 10 r.STCD,sum(r.DRP) as DRP_SUM ,b.STNM,b.STLC, c.LYNAME
from RWDB.dbo.ST_PPTN_R r
left join RWDB.dbo.ST_STBPRP_B b on r.STCD=b.STCD
left join RWDB.dbo.ST_RVFCCH_B c on b.ADDVCD=c.ADDVCD
where r.TM >= DATEADD(hour,-1,GETDATE())
and c.LYNAME = '某个流域'
group by r.STCD, b.STNM, b.STLC, c.LYNAME
order by sum(r.DRP) desc
如果是查询某个流域/县市的前10名,在条件里加上就可以。
如果是要查询各个流域/县市的前10名,可以用开窗函数和row_number()/RANK()来获取。
select
top 10 r.STCD,sum(r.DRP) as DRP_SUM ,b.STNM,b.STLC,b.BSNM
from
RWDB.dbo.ST_PPTN_R r left join RWDB.dbo.ST_STBPRP_B b
on
r.STCD=b.STCD
where
r.TM >= DATEADD(hour,-3,GETDATE()) and b.BSNM='需要的流域名称'
group by r.STCD,b.STNM,b.STLC,b.BSNM
order by sum(r.DRP) desc
按你的意思应该是这样的,但是没有具体的示例也不确定。
select top 10 *
from RWDB.dbo.ST_STBPRP_B b with (nolock)
inner join (
select STCD,sum(DRP) as DRP_SUM
from RWDB.dbo.ST_PPTN_R with (nolock)
where TM >= DATEADD(hour,-3,GETDATE())
group by STCD
) r on b.STCD = r.STCD
where BSNM = '流域名称'
order by DRP_SUM desc
通常来讲,需要进行聚合的数据单独放到子查询里,然后将聚合后的数据再与期待输出的主表进行关联,这样就很方便操作了
以下答案基于ChatGPT与GISer Liu编写:
假设你已经有一个能够将站点和其所属流域或县市对应的表 ST_STBASIN_B,其中 STCD 和 BASIN_CODE 或 COUNTY_CODE 是关联字段。可以使用以下 SQL 查询语句,根据流域或县市划分,找出指定时间范围内一小时雨量最大的10个站:
-- 以流域划分
选择 TOP 10 R.STCD, SUM(R.DRP) AS DRP_SUM, b.STNM, b.STLC, s.BASIN_CODE
从 RWDB.dbo.ST_PPTN_R R
左连接 RWDB.dbo.ST_STBPRP_B b 在 r.STCD = b.STCD 上
左联接 RWDB.dbo.ST_STBASIN_B 在 b.STCD = s.STCD 上
其中 r.TM >= DATEADD(hour, -3, GETDATE()) 和 s.BASIN_CODE = '指定流域代码'
GROUP BY r.STCD, b.STNM, b.STLC, s.BASIN_CODE
按总和排序(r.DRP) 描述
-- 以县市划分
选择 TOP 10 r.STCD, SUM(r.DRP) AS DRP_SUM, b.STNM, b.STLC, s.COUNTY_CODE
从 RWDB.dbo.ST_PPTN_R R
左连接 RWDB.dbo.ST_STBPRP_B b 在 r.STCD = b.STCD 上
左联接 RWDB.dbo.ST_STBASIN_B 在 b.STCD = s.STCD 上
其中 r.TM >= DATEADD(hour, -3, GETDATE()) 和 s.COUNTY_CODE = '指定县市代码'
GROUP BY r.STCD, b.STNM, b.STLC, s.COUNTY_CODE
按总和排序(r.DRP) 描述
在以上查询语句中,通过左连接方式关联了三张表,其中 ST_PPTN_R 表存储了雨量信息,ST_STBPRP_B 表存储了站点信息,ST_STBASIN_B 表存储了站点和流域/县市的对应关系。使用 WHERE 语句指定时间范围和指定的流域或县市代码进行筛选,并使用 GROUP BY 对结果进行分组,以计算每个站点一小时的总雨量。最后使用 ORDER BY 将总雨量按照从大到小的顺序排序,取出前 10 个即为一小时雨量最大的 10 个站。
SELECT t1. * , t2. *
FROM table1 t1, table2 t2
WHERE t1.column1 = t2.column1
SELECT TOP 10 r.STCD, SUM(r.DRP) AS DRP_SUM, b.STNM, b.STLC, b.LB
FROM RWDB.dbo.ST_PPTN_R r
LEFT JOIN RWDB.dbo.ST_STBPRP_B b ON r.STCD = b.STCD
WHERE r.TM >= DATEADD(hour, -3, GETDATE()) AND b.LB = '某一流域'
GROUP BY r.STCD, b.STNM, b.STLC, b.LB
ORDER BY SUM(r.DRP) DESC
其中 b.LB 是流域或县市的字段名,'某一流域' 是需要筛选的流域或县市名称。如果需要按照县市进行分组,则将 b.LB 改为相应的县市字段名即可。