python爬虫无有效内容
使用python爬虫制作的简易网页采集器,无法返回有效内容,还是乱码
python爬虫源码:
import requests
url = "https://www.baidu.com/s?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
}
kw = input('请输入您想查找的内容:')
password = {
'wb': kw
}
resp = requests.get(url, params=password, headers=headers)
with open(kw+".html", "w", encoding="utf-8") as fp:
fp.write(resp.text)
print("ok")
爬虫返回的内容是:
html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>ç¾åº¦å®å
¨éªè¯title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="apple-mobile-web-app-capable" content="yes">
<meta name="apple-mobile-web-app-status-bar-style" content="black">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0">
<meta name="format-detection" content="telephone=no, email=no">
<link rel="shortcut icon" href="https://www.baidu.com/favicon.ico" type="image/x-icon">
<link rel="icon" sizes="any" mask href="https://www.baidu.com/img/baidu.svg">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">
<link rel="stylesheet" href="https://ppui-static-wap.cdn.bcebos.com/static/touch/css/api/mkdjump_aac6df1.css" />
head>
<body>
<div class="timeout hide-callback">
<div class="timeout-img">div>
<div class="timeout-title">ç½ç»ä¸ç»åï¼è¯·ç¨åéè¯div>
<button type="button" class="timeout-button">è¿åé¦é¡µbutton>
div>
<div class="timeout-feedback hide-callback">
<div class="timeout-feedback-icon">div>
<p class="timeout-feedback-title">é®é¢åé¦p>
div>
<script src="https://ppui-static-wap.cdn.bcebos.com/static/touch/js/mkdjump_v2_2d634b8.js">script>
body>
html>
这种情况怎么解决!谢谢
有用请采纳
get()返回的resq你得看看encoding是不是UTF-8的编码,如果不是得重新设置。
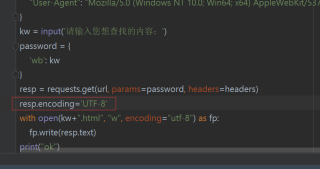
该回答引用ChatGPT
根据你提供的代码和返回的结果来看,爬虫返回的确实是乱码,这通常是由于编码问题导致的。你的代码中使用了UTF-8编码,但是返回的网页使用了其他编码方式,所以导致了乱码。解决方法是在请求头中设置正确的编码方式。你可以尝试将请求头中的Content-Type设置为"text/html; charset=gbk",gbk是常用的中文编码方式之一。修改后的代码如下:
import requests
url = "https://www.baidu.com/s?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Content-Type": "text/html; charset=gbk"
}
kw = input('请输入您想查找的内容:')
password = {
'wb': kw
}
resp = requests.get(url, params=password, headers=headers)
with open(kw+".html", "w", encoding="utf-8") as fp:
fp.write(resp.text)
print("ok")
如果还是无法解决乱码问题,可以尝试打印出响应的编码方式,查看一下实际使用的编码方式:
print(resp.encoding)
然后根据实际编码方式修改请求头中的Content-Type即可。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7551280
- 你也可以参考下这篇文章:python基础内容整理