pytorch训练完一个epoch计算验证集精度时怎样释放显存
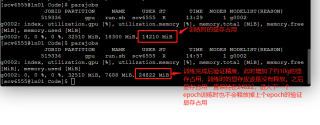
如题,在用pytorch训练语义分割模型时,训练完一个epoch后想计算验证集精度再进行第二次训练,但是从显存上来看,在验证时没有释放训练集的显存,此时显存的占用好像是训练过程与验证过程的集合。
请问能不能在验证时释放掉训练过程的显存占用,然后在下一个epoch训练时再释放掉上一次epoch验证时的显存占用?
基于Monster 组和GPT的调写:
使用torch.cuda.empty_cache()函数手动释放显存。如果想要在每个epoch的训练结束后释放训练集显存,可以在每个epoch结束时调用该函数。
同时,也可以在每个epoch的验证开始时手动释放训练集显存,以便给验证集提供更多的显存。可以在验证开始前调用torch.cuda.empty_cache()函数。
以下是一个示例代码片段,演示如何在每个epoch的训练结束和验证开始时手动释放显存:
import torch
# 定义训练和验证函数
def train(model, train_loader, optimizer, criterion):
# 训练过程中的代码
torch.cuda.empty_cache() # 释放训练集显存
def validate(model, val_loader, criterion):
torch.cuda.empty_cache() # 释放训练集显存
# 验证过程中的代码
# 在训练循环中调用 train() 和 validate()
for epoch in range(num_epochs):
train(model, train_loader, optimizer, criterion)
validate(model, val_loader, criterion)
torch.cuda.empty_cache() # 释放验证集显存
- 建议你看下这篇博客👉 :pytorch中使用numpy生成随机数每个epoch都一样
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^