python爬虫一个小问题
下载出现问题,应该是name|+"zip"这里
可是不知道怎么办啊
```python
import wget
import requests # 数据请求模块注意版本
import parsel # 数据解析模块
# noinspection PyUnresolvedReferences
import csv
import csv
from lxml import etree
import csv
import time
from requests import Response
for page in range(2,3):
print(f'正在采集第{page}页的内容')#提示行
time.sleep(2)#间隔时间
# 第一步网址
url = f'http://www.zhongkao.com/zyk/czlxt/ceyw/index_{page}.shtml'#http://www.zhongkao.com/zyk/czlxt/ceyw/
# 第二步伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}#易出昌号前后加引号,不要有空格
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
#print(response)
selector = parsel.Selector(response.text)#类型转换注意大写转换为selector对象
#print(selector)
lis = selector.css('.text_list1 li')
#print(lis)
for li in lis:
wangzhi = li.css('.title a::attr(href)').get()
response = requests.get(url=wangzhi, headers=headers)
response.encoding = 'gb2312'
selector = parsel.Selector(response.text) # 类型转换注意大写转换为selector对象
#print(selector)
pic = selector.css('td a:nth-child(2)::attr(href)').get()
name = selector.css(' td span::text').get()
n= name +".zip"
wget.download(pic, out=n)
```
你的原代码拷贝过来执行的话,name返回的是None,也就是说你的选择器没有找到你期望的内容,调试代码修改如下:
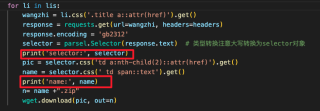
注意看打印输出的内容:

所以检查下css选择器的代码是否正确吧
有帮助的话,请点采纳~
该回答引用ChatGPT
在 Python 中,文件名不能包含某些特殊字符(例如 |),否则会导致无法创建或保存该文件。
你可以将 name 字符串中的特殊字符替换为其他字符,以确保文件名的有效性。例如,你可以使用下面这段代码来替换 name 字符串中的所有非字母数字字符:
import re
name = re.sub(r'\W+', '', name) # 去除非字母数字字符
n = name + '.zip'
这样可以保证 n 的值是合法的文件名,从而避免下载出现问题。
在这个程序中,name 变量包含了要保存的文件名,但是文件名中可能包含一些非法字符,例如 :、/ 等,这些字符在文件名中是不允许的,可能会导致文件下载失败。你可以使用 Python 标准库中的 re 模块来去掉文件名中的非法字符,例如:
import re
n = re.sub(r'[^\w\-. ]', '', name) + '.zip'
这段代码使用了正则表达式,把文件名中非字母、数字、下划线、点和短横线以外的字符全部替换成空白,然后加上 .zip 后缀作为文件名。这样就可以避免出现文件名中的非法字符了。
以下答案引用自GPT-3大模型,请合理使用:
试试这段代码:
```python
import wget
import requests # 数据请求模块注意版本
import parsel # 数据解析模块
# noinspection PyUnresolvedReferences
import csv
import csv
from lxml import etree
import csv
import time
from requests import Response
for page in range(2,3):
print(f'正在采集第{page}页的内容')#提示行
time.sleep(2)#间隔时间
# 第一步网址
url = f'http://www.zhongkao.com/zyk/czlxt/ceyw/index_{page}.shtml'#http://www.zhongkao.com/zyk/czlxt/ceyw/
# 第二步伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}#易出昌号前后加引号,不要有空格
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
#print(response)
selector = parsel.Selector(response.text)#类型转换注意大写转换为selector对象
#print(selector)
lis = selector.css('.text_list1 li')
#print(lis)
for li in lis:
wangzhi = li.css('.title a::attr(href)').get()
response = requests.get(url=wangzhi, headers=headers)
response.encoding = 'gb2312'
selector = parsel.Selector(response.text) # 类型转换注意大写转换为selector对象
#print(selector)
pic = selector.css('td a:nth-child(2)::attr(href)').get()
name = selector.css(' td span::text').get().replace(" ","") # 文件名中去掉空格
n= name +".zip"
wget.download(pic, out=n)
```
如果我的回答解决了您的问题,请采纳我的回答
- 建议你看下这篇博客👉 :Python遇到的一些小问题
- 你还可以看下python参考手册中的 python- 接下来?