python,django,多线程,事务
问题:如何操作使多线程达到普通方法调用的效果,使一次子线程失败,所有子线程及主线程保持一致,不去操作数据库
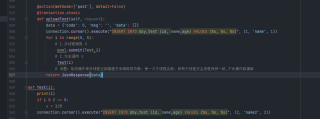
@action(methods=['post'], detail=False)
@transaction.atomic
def uploadTest(self, request):
data = {'code': 0, 'msg': '', 'data': []}
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (1, 'name', 1))
for i in range(0, 5):
# 1.多线程调用 X
pool.submit(Test,i)
# 2.方法调用 √
Test(i)
# 问题:如何操作使多线程达到普通方法调用的效果,使一次子线程失败,所有子线程及主线程保持一致,不去操作数据库
return JsonResponse(data)
def Test(i):
print(i)
if i % 2 == 0:
a = 1/0
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
基于Monster 组和GPT的调写:
要让多线程达到普通方法调用的效果,使一次子线程失败,所有子线程及主线程保持一致,可以使用以下步骤:
import threading
lock = threading.Lock() # 创建线程锁
@action(methods=['post'], detail=False)
def uploadTest(self, request):
data = {'code': 0, 'msg': '', 'data': []}
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (1, 'name', 1))
threads = []
for i in range(0, 5):
t = threading.Thread(target=Test, args=(i,))
threads.append(t)
t.start()
# 等待所有子线程结束
for t in threads:
t.join()
return JsonResponse(data)
def Test(i):
try:
print(i)
if i % 2 == 0:
raise Exception("Exception in thread {}".format(i))
with lock:
# 线程锁保证多个线程不会同时修改数据库
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
except Exception as e:
# 异常捕获,保证子线程和主线程都能处理异常
with lock:
print(e)
在这个例子中,我们使用ThreadPoolExecutor创建一个具有最大工作线程数为5的线程池。然后,我们将上传数据的任务添加到线程池中,使用as_completed方法迭代所有线程,并捕获可能抛出的异常。如果有任何一个线程抛出异常,则向所有线程发送一个停止信号。当所有线程完成时,我们检查是否有任何线程抛出了异常。如果有,则将异常重新抛出,以便在主线程中处理。
该回答引用ChatGPT
要达到多线程和方法调用相同的效果,可以使用Python的multiprocessing模块来创建子进程。多线程和多进程最大的区别在于,多线程共享进程内的内存,而多进程各自拥有一份独立的内存空间,因此多进程之间的错误不会互相干扰。所以,如果想要在多线程的情况下保持一致,可以通过多进程来实现。
from multiprocessing import Process
from django.db import connection
from django.http import JsonResponse
def uploadTest(request):
data = {'code': 0, 'msg': '', 'data': []}
connection.cursor().execute("INSERT INTO bby_test (id, name, age) VALUES (%s, %s, %s)", (1, 'name', 1))
processes = []
for i in range(0, 5):
process = Process(target=Test, args=(i,))
process.start()
processes.append(process)
for process in processes:
process.join()
return JsonResponse(data)
def Test(i):
print(i)
if i % 2 == 0:
raise Exception('An error occurred')
connection.cursor().execute("INSERT INTO bby_test (id, name, age) VALUES (%s, %s, %s)", (2, 'name2', 2))
在使用多线程时,如果想要达到普通方法调用的效果,可以使用线程锁(threading.Lock)和异常捕获来实现。具体操作如下:
- 定义线程锁
在函数外定义一个线程锁,例如:
csharp
lock = threading.Lock()
- 在需要操作数据库的代码块中获取线程锁
在 Test 函数中的操作数据库的代码块之前获取线程锁,例如:
perl
with lock: connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
- 捕获异常并回滚事务
在 Test 函数中捕获异常,如果出现异常,使用 transaction.set_rollback(True) 回滚事务,例如:
python
def Test(i): print(i) try: if i % 2 == 0: a = 1/0 with lock: connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2)) except: transaction.set_rollback(True)完整代码如下:
python
import threading from django.db import connection, transaction from django.http import JsonResponse lock = threading.Lock() def Test(i): print(i) try: if i % 2 == 0: a = 1/0 with lock: connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2)) except: transaction.set_rollback(True) def uploadTest(self, request): data = {'code': 0, 'msg': '', 'data': []} connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (1, 'name', 1)) for i in range(0, 5): t = threading.Thread(target=Test, args=(i,)) t.start() return JsonResponse(data)在这个例子中,如果有一个子线程出现异常,所有子线程以及主线程都会回滚事务,从而保持一致,不会操作数据库。
可以使用threading.Event来进行线程间通信,并将该事件传递到子线程中
import threading
from django.db import connection
def worker(i, event):
print(i)
if i % 2 == 0:
event.set() # 设置 event,通知其他线程停止执行
return
with connection.cursor() as cursor:
cursor.execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
def uploadTest(self, request):
data = {'code': 0, 'msg': '', 'data': []}
event = threading.Event() # 创建 Event 对象
threads = []
for i in range(0, 5):
t = threading.Thread(target=worker, args=(i, event))
threads.append(t)
t.start()
# 等待所有子线程执行完成
for t in threads:
t.join()
if event.is_set():
# 有子线程发生异常
data['msg'] = 'One or more threads failed'
event.clear() # 清除 event
else:
data['msg'] = 'All threads completed successfully'
return JsonResponse(data)
- 可以看下python参考手册中的 python- 多线程
如果要使多线程达到普通方法调用的效果,使一次子线程失败,所有子线程及主线程保持一致,可以考虑使用分布式锁来实现。
具体地,可以使用一个分布式锁来控制所有线程对数据库的访问。当一个线程开始访问数据库时,首先需要获取分布式锁,然后执行数据库操作。如果出现异常,就需要释放分布式锁。其他线程在访问数据库前也需要获取分布式锁,以确保所有线程访问数据库的顺序和时序一致。
使用分布式锁可以保证所有线程对数据库的操作顺序和时序一致,同时也可以避免一次子线程失败对其他线程和主线程造成影响。下面是一个简单的使用分布式锁的示例代码:
import threading
import redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)
def Test(i):
print(i)
if i % 2 == 0:
raise Exception('Error')
redis_lock = redis_client.lock('mylock') # 获取分布式锁
try:
redis_lock.acquire()
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
except Exception as e:
raise e
finally:
redis_lock.release() # 释放分布式锁
@transaction.atomic
def uploadTest(self, request):
data = {'code': 0, 'msg': '', 'data': []}
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (1, 'name', 1))
threads = []
for i in range(0, 5):
t = threading.Thread(target=Test, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
return JsonResponse(data)
在这个示例代码中,我们使用了 Redis 作为分布式锁的存储工具。首先在 Test 函数中获取分布式锁,然后执行数据库操作。如果出现异常,就需要释放分布式锁。其他线程在访问数据库前也需要获取分布式锁,以确保所有线程访问数据库的顺序和时序一致。最后,我们使用 join() 方法等待所有线程执行完毕。