django多线程环境事务
问题:python,django多线程读取ecel并导入到数据库,主线程事务有效,子线程事务失效
代码截图
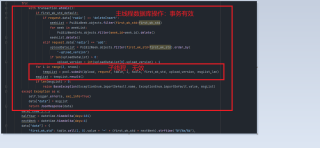
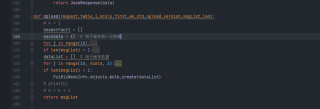
问题简化版:
@action(methods=['post'], detail=False)
@transaction.atomic
def uploadTest(self, request):
data = {'code': 0, 'msg': '', 'data': []}
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (1, 'name', 1))
for i in range(0, 5):
# 1.多线程调用 X
pool.submit(Test,i)
# 2.方法调用 √
Test(i)
# 问题:如何操作使多线程达到普通方法调用的效果,使一次子线程失败,所有子线程及主线程保持一致,不去操作数据库
return JsonResponse(data)
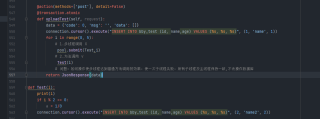
def Test(i):
print(i)
if i % 2 == 0:
a = 1/0
connection.cursor().execute("INSERT INTO bby_test (id, name,age) VALUES (%s, %s, %s)", (2, 'name2', 2))
基于Monster 组和GPT的调写:
在你的情况下,主线程中的事务是有效的,因为它是由Django框架自动创建和管理的。但是在子线程中,你需要手动创建事务,并手动提交或回滚,否则事务将不会生效。
你可以通过使用django.db.connections来在子线程中手动创建和管理数据库连接和事务。以下是一个示例代码:
from django.db import connections
def import_data():
# 从excel中读取数据
# ...
# 获取数据库连接
connection = connections['default']
# 开始事务
with connection.cursor() as cursor:
cursor.execute("BEGIN")
try:
# 将数据导入到数据库中
# ...
# 提交事务
with connection.cursor() as cursor:
cursor.execute("COMMIT")
except:
# 回滚事务
with connection.cursor() as cursor:
cursor.execute("ROLLBACK")
在子线程中,你需要使用connections来获取数据库连接,并使用cursor来手动执行SQL语句。在执行SQL语句之前,你需要使用BEGIN命令来开启一个事务,在执行完SQL语句后,使用COMMIT命令提交事务,如果出现异常,则需要使用ROLLBACK命令回滚事务
根据你提供的截图,我看到你在主线程中使用了@transaction.atomic()装饰器来保证主线程的事务操作的原子性。然而,你的子线程中没有使用这个装饰器,这可能导致子线程的事务操作失效。
Django的数据库连接是线程本地的,这意味着每个线程都有自己的数据库连接。因此,如果你在子线程中进行数据库操作,你需要在子线程中手动创建一个数据库连接,然后使用@transaction.atomic(using=DATABASE_ALIAS)来为子线程的事务操作添加原子性。
你可以像这样修改你的代码,为子线程添加原子性:
import threading
from django.db import transaction
from .models import TableA
def import_excel_to_db(file_path):
# 读取 Excel 文件并导入到数据库
...
@transaction.atomic()
def import_data(file_path_list):
# 使用 @transaction.atomic() 保证主线程的事务操作的原子性
for file_path in file_path_list:
# 创建子线程并启动
t = threading.Thread(target=import_excel_to_db, args=(file_path,))
t.start()
# 等待子线程完成
t.join()
在子线程中,你可以使用以下代码来创建数据库连接和为事务操作添加原子性:
def import_excel_to_db(file_path):
with transaction.atomic(using='default'):
# 读取 Excel 文件并导入到数据库
...
在这个例子中,我假设你的数据库别名为 default,你可以将 using 参数替换为你自己的数据库别名。
最后,你需要注意的是,在主线程中等待子线程完成的代码t.join()放在了循环中,这会导致每次循环都会等待子线程完成,这可能会影响你的程序性能。你可以将t.join()放在循环外面,等待所有子线程完成后再继续执行主线程的代码。
问题可能是由于Django的数据库连接是线程局部变量导致的,因此在子线程中无法获取到Django的数据库连接,从而导致事务失效。
可以尝试在子线程中重新获取数据库连接并在子线程中使用它,具体实现如下:
- 在主线程中获取数据库连接,将其保存到全局变量中。
python
# main thread from django.db import transaction, connections db_conn = connections['default'] # 获取数据库连接 @transaction.atomic(using='default') def import_excel(): # 读取excel文件并导入数据到数据库 pass if __name__ == '__main__': import_excel() # 在主线程中调用导入数据的函数
- 在子线程中获取数据库连接并使用。
python
# sub thread from django.db import connections def handle_data(data): db_conn = connections['default'] # 在子线程中获取数据库连接 with db_conn.cursor() as cursor: cursor.execute("INSERT INTO table_name (column1, column2) VALUES (%s, %s)", (data['column1'], data['column2'])) db_conn.commit() if __name__ == '__main__': data = {'column1': 'value1', 'column2': 'value2'} t = threading.Thread(target=handle_data, args=(data,)) t.start() # 启动子线程处理数据在子线程中重新获取数据库连接,可以避免线程局部变量的问题。在使用完数据库连接后,需要手动调用
commit()提交事务。
在使用多线程读取 Excel 并导入数据库时,如果子线程使用了新的数据库连接和事务,那么在主线程提交事务之前,子线程中所做的操作并不会被提交到数据库中。因此,主线程中的事务是有效的,而子线程中的事务是失效的。
- 这篇文章:Django实现数据库事务操作 也许能够解决你的问题,你可以看下