Pandas中如何选择指定index其上一行的index?

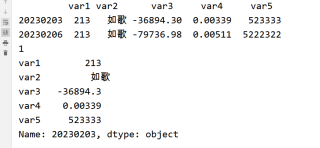
如上图。
日期这一列已经设置成了index,如果我们选定日期“20230206”的时候,如何让它上面这行的“20230203”参与运算呢?
望采纳我的,shift是对数据行进行上下平移,并不能解决您的问题,我的解决思路是获取当前行的下标-1就是上一行的数据:
import pandas as pd
data = {'var1': ['213', '213'],
'var2': ['如歌', '如歌'],
'var3': [-36894.30, -79736.98],
'var4': [0.003390, 0.005110],
'var5': [523333, 5222322]
}
df = pd.DataFrame(data, index=[20230203, 20230206])
print(df)
# 选择上一行
row = df.iloc[df.index.values.tolist().index(20230206)-1]
# 打印结果
print(row)
运行结果:
- 这篇博客也许可以解决你的问题👉 :pandas的索引 index的用途
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
该回答引用ChatGPT
参考下面代码
import pandas as pd
# 创建示例DataFrame对象
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}, index=pd.to_datetime(['2022-02-12', '2022-02-13', '2022-02-14']))
# 选择指定索引值的上一行
index_to_select = pd.to_datetime(['2022-02-14'])
previous_row = df.shift(1).loc[index_to_select]
print(previous_row)
可以使用Pandas中的shift函数来选择指定index的上一行数据,例如:
假设DataFrame为df,日期这一列已经设置成了index,可以使用以下代码来选取日期为“20230206”的行及其上一行数据:
selected_date = '20230206'
selected_row = df.loc[selected_date]
prev_row = df.loc[selected_date].shift(1)
其中,为选定日期的行数据,selected_rowprev_row为选定日期的上一行数据。shift(1)表示向上移动一行。
你可以在选定日期的行数据和上一行数据之间进行任意的运算。需要注意的是,如果选定的日期是第一行,则上一行数据将为NaN。