关于 java 利用jsoup爬取图片的问题?
利用jsoup爬取网站图片,
//imgStr为图片的url
Connection.Response response = Jsoup.connect(imgStr).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76")
.ignoreContentType(true).execute();
//调用下载
loadImg(response.bodyAsBytes());
图片下载本地
public void loadImg(byte[] bt) throws IOException {
String imgName ;
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHHmmss");//设置日期格式
imgName = df.format(new Date()) +".jpg";
ByteArrayInputStream stream = new ByteArrayInputStream(bt);
FileUtils.copyInputStreamToFile(stream, new File("D://picture2//"+ imgName ));
System.out.println("下载完成");
}
可是下载的图片时损坏状态。于是我用notepad+将损坏图片打开,发现竟然时html代码。
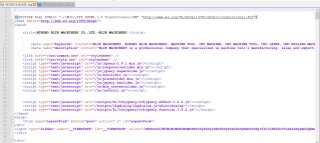
有的网站用上面的代码是可以下载图片,但是有的网站就会遇到上面的问题。
我想问一下这是哪里出了问题,该怎么解决?
每个网站的数据请求方式可能不一样,甚至有些网站不让下载,能够检测到不是人工下载。你可以手动打开那个不能下载的url,复制到浏览器上打开看能否正常显示,其次url是否发生了变化。望采纳!!
以下答案引用自GPT-3大模型,请合理使用:
。
因为网站内容变化较快,所以代码无法一一给出。 问题出在哪里呢?我该怎么解决这个问题?
可能是网站的链接变化了,导致jsoup无法获取到图片内容。 你可以尝试使用正则表达式来过滤图片的链接。 例如:
Connection.Response response = Jsoup.connect(imgStr).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76")
。ignoreContentType(true).execute();
//调用下载
loadImg(response.bodyAsBytes(), "img.jpg");
如果我的回答解决了您的问题,请采纳我的回答
- 文章:简单使用Java之Jsoup解析网页 中也许有你想要的答案,请看下吧