如何使用xpath数据解析遇到的数据错位问题?
使用xpath数据解析遇到的数据错位问题?求提供解决方案
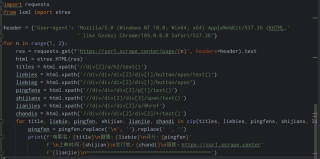
代码如下:
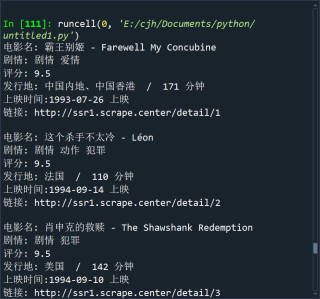
输出结果为:
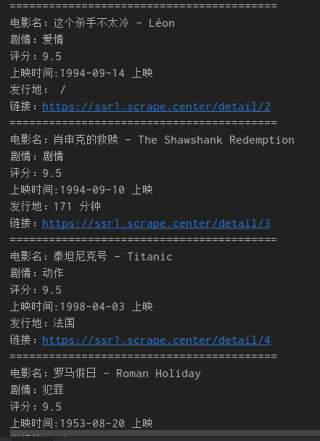
原网页的内容为:

爬取的内容中:剧情和发行地内容明显错位问题
求解决
data=html.xpath('//*[@class="p-h el-col el-col-24 el-col-xs-9 el-col-sm-13 el-col-md-16"]')
scores=html.xpath('//*[@class="score m-t-md m-b-n-sm"]//text()')
for n,i in enumerate(data):
name=i.xpath('./a//text()')
print('电影名:',name[1])
categories=i.xpath('./div/button')
s=''
for j in categories:
dd=j.xpath('./span//text()')
for k in dd:
s=f"{s}{k} "
print('剧情:',s)
s=scores[n].replace('\n','')
s=s.replace(' ','')
print('评分:',s)
info1=i.xpath('./div[2]')
s=''
for j in info1:
dd=j.xpath('./span//text()')
for k in dd:
s=f"{s}{k} "
print('发行地:',s)
info2=i.xpath('./div[3]')
for j in info2:
dd=j.xpath('.//text()')
if len(dd)>1:
print(f"上映时间:{dd[1]} ")
href=i.xpath('./a/@href')
print('链接:',f"http://ssr1.scrape.center{href[0]}\n")
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7627878
- 你也可以参考下这篇文章:数据解析——xpath解析