CBIS-DDSM kaggle 资料处理
以下是資料下載處:
https://www.kaggle.com/datasets/awsaf49/cbis-ddsm-breast-cancer-image-dataset
下載後打開會有兩個子文件夾 csv和jpeg如下:

jpeg裡面又有好幾個文件夾:

"隨機"裝著mamogramm的 full mamogramm, cropped images 和 ROI images,
看似只能够过csv档之间的交叉比对才能够找出真正相对应的 full mamogramm, cropped images, 和ROI images.
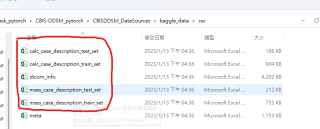
我想要把真正对应的 full mamogramm, cropped images, 和ROI images.分别装在同样的文件夹里面。
感觉很复杂, 有人做过或是会做的吗?
#复制文件函数
def copy_files(l,dd):
for n in range(len(dd)):
d=re.findall(r'/(.*)/', dd.loc[n,'image file path'])[0]
a=re.findall(r'/(.*)', d)[0]
old_path=f"D:/archive/jpeg/{a}"
full_filenames=os.listdir(old_path)
os.makedirs(f"d:/images/{n+l}")
for i in full_filenames:
shutil.copy(f"{old_path}/{i}", f'd:/images/{n+l}/full_{n+l}.jpg')
d=re.findall(r'/(.*)/', dd.loc[n,'cropped image file path'])[0]
a=re.findall(r'/(.*)', d)[0]
old_path=f"D:/archive/jpeg/{a}"
if os.path.exists(old_path):
cropped_filenames=os.listdir(old_path)
for i in cropped_filenames:
if i[0]=='1':
shutil.copy(f"{old_path}/{i}", f'd:/images/{n+l}/cropped_{n+l}.jpg')
else:
shutil.copy(f"{old_path}/{i}", f'd:/images/{n+l}/roi_{n+l}.jpg')
# dd=pd.read_csv('D:/archive/csv/dicom_info.csv')
# info=dd[['image_path','PatientName']]
dd=pd.read_csv('D:/archive/csv/calc_case_description_test_set.csv')
copy_files(0,dd)
l=len(dd)
dd=pd.read_csv('D:/archive/csv/calc_case_description_train_set.csv')
copy_files(l,dd)
l=l+len(dd)
dd=pd.read_csv('D:/archive/csv/mass_case_description_test_set.csv')
copy_files(l,dd)
l=l+len(dd)
dd=pd.read_csv('D:/archive/csv/mass_case_description_train_set.csv')
copy_files(l,dd)
这个过程可以使用Pandas和OS库在Python中实现。确切的代码将取决于 csv 文件的结构和所需的输出。
下面是一个使用 Pandas 库的 Python 解决方案示例:
import pandas as pd
import os
import shutil
# Read the csv files into a Pandas dataframe
df = pd.read_csv("file.csv")
# Clean and preprocess the data in the dataframe
df = df.dropna()
df = df.drop_duplicates()
df["filename"] = df["filename"].str.strip()
# Create separate folders for each image category
if not os.path.exists("full_mammograms"):
os.makedirs("full_mammograms")
if not os.path.exists("cropped_images"):
os.makedirs("cropped_images")
if not os.path.exists("ROI_images"):
os.makedirs("ROI_images")
# Use a loop to iterate through the images and move each image to its corresponding folder
for index, row in df.iterrows():
filename = row["filename"]
category = row["category"]
src_path = os.path.join("jpeg", filename)
if category == "full_mammogram":
dst_path = os.path.join("full_mammograms", filename)
elif category == "cropped_image":
dst_path = os.path.join("cropped_images", filename)
elif category == "ROI_image":
dst_path = os.path.join("ROI_images", filename)
else:
continue
shutil.copy2(src_path, dst_path)
此代码首先使用“read_csv
接下来,代码为每个图像类别创建单独的文件夹:“full_mammograms”、“cropped_images”和“ROI_images”。然后使用循环循环访问图像,并根据数据帧的“类别”列中的值将每个图像移动到其相应的文件夹。'shutil.copy函数用于将图像从“JPEG”文件夹复制到相应文件夹中的新位置。
注意:此代码假定“jpeg”文件夹中的文件名与csv文件中的名称匹配,并且csv文件中的“类别”列包含每个图像的正确标签。您可能需要调整代码以适应 csv 文件和图像的特定结构
不知道这个实例对你是否有帮助:医学影像数据 CBIS-DDSM 图形分类,链接:https://aistudio.baidu.com/aistudio/projectdetail/3493509