c# 如何 获取 webBrowser 里面网页 data的值
c# 如何 获取 webBrowser 里面网页 data的值(如图获取这个值:441823011943208 )
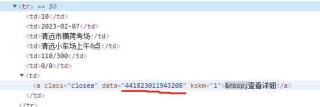
”该回答引用ChatGPT“
请参考下面的解决方案,如果可行,还请点击 ,采纳 ,感谢支持!
请测试下面的代码 :
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
HtmlElementCollection elements = webBrowser1.Document.GetElementsByTagName("a");
foreach (HtmlElement element in elements)
{
if (element.GetAttribute("class") == "closea")
{
string data = element.GetAttribute("data");
if (!string.IsNullOrEmpty(data))
{
Console.WriteLine("Data value: " + data);
}
}
}
}
上面的代码在WebBrowser的DocumentCompleted事件里面实现。首先,它通过GetElementsByTagName方法获取所有的a标签,然后在foreach循环里面遍历每一个元素。如果当前元素的class属性等于"closea",则通过GetAttribute方法获取它的data属性的值。最后,通过Console.WriteLine方法输出这个data值。
使用WebBrowser.Document.GetElementById()方法获取HTML元素,然后使用HtmlElement.GetAttribute()方法获取元素的属性值。
使用WebBrowser.Document.GetElementsByTagName()方法获取HTML元素,然后使用HtmlElement.GetAttribute()方法获取元素的属性值。
使用WebBrowser.Document.InvokeScript()方法调用JavaScript函数,然后获取JavaScript函数的返回值。
WebBrowser 控件裡有個 Document 属性
可以用来访问当前加载的 HTML 页面
使用防問到的页面中的 GetElementById 方法可以查找 HTML 元素,最終获取该元素的值
可以用下面這個簡單的代碼來做操作
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
HtmlElement element = webBrowser1.Document.GetElementById("elementId");
if (element != null)
{
string value = element.InnerText;
}
}
需要注意的是在这种情况下,你要知道该元素的 id 值為何
如果想要访问其他元素的值,也可以通过使用 HtmlElementCollection 或类似的方法来对页面进行更多的遍历。
你发个包,然后接收,并将含有data的值搜索出来。
//using System.IO;
try
{
WebClient webClient = new WebClient();
webClient.Credentials = CredentialCache.DefaultCredentials;//获取或设置用于向Internet资源的请求进行身份验证的网络凭据
Byte[] pageData = webClient.DownloadData("http://ikun.com");
//string pageHtml = Encoding.Default.GetString(pageData); //如果获取网站页面采用的是GB2312,则使用这句
string pageHtml = Encoding.UTF8.GetString(pageData); //如果获取网站页面采用的是UTF-8,则使用这句
using (StreamWriter sw = new StreamWriter("d:\\dataouput.txt"))//将获取的内容写入文本
{
htm = sw.ToString();//测试StreamWriter流的输出状态,非必须
sw.Write(pageHtml);
}
}
catch (WebException webEx)
{
Console.W
}
- 你可以参考下这篇文章:【C#】[网络]WebBrowser网页操作之提取获取元素和标签(完整篇)
You can extract the data from a webpage in a Windows Forms WebBrowser control using the Document property. You can then use the GetElementById method to get a reference to a specific HTML element, and access its properties to retrieve the data you're interested in. Here's an example that retrieves the text of an element with an ID of "example":
string data;
HtmlElement element = webBrowser1.Document.GetElementById("example");
if (element != null)
{
data = element.InnerText;
}
If the data you're interested in is stored in an attribute of an element, such as the value attribute of an input element, you can access it like this:
string data;
HtmlElement element = webBrowser1.Document.GetElementById("example");
if (element != null)
{
data = element.GetAttribute("value");
}