使用python中pandas进行数据分析
使用US_Crime_Rates_1960_2014.csv,根据1991-2014年的数据制作一条回归曲线,预测2019年的各个犯罪条目的犯罪率。
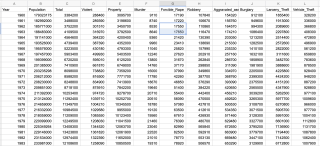
“该回答引用ChatGPT”
参考下面的解决方案,请测试代码的可行性,如果可行,还请点击 采纳,感谢支持!
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
# 读取csv文件
df = pd.read_csv("crime_data.csv")
# 取Year和Total两列作为训练数据
X = df[['Year']]
y = df['Total']
# 训练线性回归模型
model = LinearRegression()
model.fit(X, y)
# 预测2019年的总犯罪数
X_pred = np.array([[2019]])
y_pred = model.predict(X_pred)
print("预测2019年的总犯罪数:", y_pred[0])
# 绘制回归曲线
plt.scatter(X, y, color='red')
plt.plot(X, model.predict(X), color='blue')
plt.xlabel("Year")
plt.ylabel("Total")
plt.show()
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7762958
- 这篇博客也不错, 你可以看下使用pandas进行数据分析,常见的报错解决(长期更新)