用YOLOv5检测胸部肿瘤之前处理步骤
最近很多人应该都知道我常上来发问,我在做医疗相关的AI images detection,但coding又不强(哭泣。
所以! 想请问: 有人知道怎么样进行以下这篇paper的data pre-processing code吗? (Reference: [https://www.researchgate.net/publication/357586797_Breast_Tumor_Detection_and_Classification_in_Mammogram_Images_Using_Modified_YOLOv5_Network]
他没有附上source code真的很讨厌(崩溃
所以, 想请问: 有人知道怎么样进行以下这篇paper的data pre-processing code吗?
流程图如下:
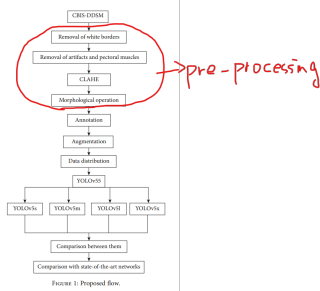
從Romoval of white borders --> Removal of artifacts muscle --> CLAHE --> Morphological operation
如下面几张图所示:
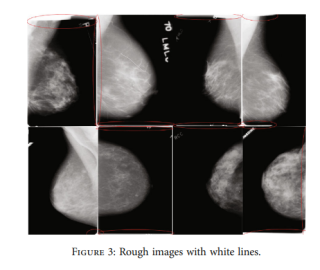
1.去白邊(Romoval of white borders)
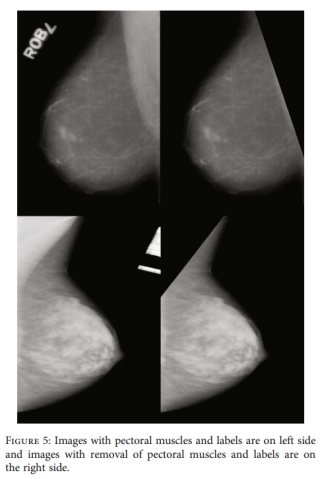
2.去肌肉組織(Removal of artifacts muscle)
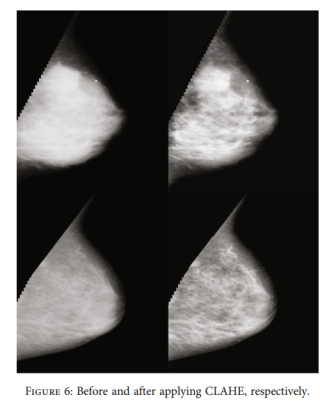
3.CLAHE
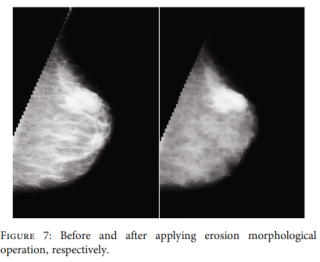
4.erosion
总归: 我希望有人能够给我这些步骤处理批量医学影像的sample code 或是给我一些“较详细”的参考文章. 来让我顺利完成这四个步骤的前处理。
最好是能封装成一个class或是def 给我 :)
PS: +价钱好谈(you know ) 我只是一个很想快速完成阶段性学习的家伙XD 總之先祝大家一路發
相关内容:如图1中所示,(1)初始阶段是去除粗糙的白色边界,(2)随后去除伪影和胸肌,(3)CLAHE 对于图像增强非常有用,(4)图像腐蚀,这是一种形态学过程,(5)在图像增强和清理完成后,进行扩充标注,(6)然后将准备好的数据输入到我们提出的YOLOv5模型中。
在本研究中,使用了YOLOv5的所有四个版本。然后将YOLOv5的原始版本与YOLOv5。在对原始版本和修改版本进行比较之后,将与最先进的网络进行比较。
你圈出的是步骤(1)~(4),3.2.1~3.2.4 给出了详细的操作细节,包括大致的参数,你确定是需要这几部分吗?如果需要可以联系。
这个太专业了吧,学一下相关的知识吧,例如Python的opencv,不然你这个问题很难办的。
按照您的问题的描述,由于涉及到比较专业化的
东西,除非有大神做过这个一模一样的,否则都
很难帮到你。所以这里给你几条建设性的建议,
希望对您的问题的解决有所帮助:
既然这个处理算法来自某一篇文章,那么你最
好的做好应该是想办法联系到作者本人,对于科
研型的论文来说,一般都会给你。毕竟可以增加
他的论文的引用。所以这是你可以采取的最好的
办法。
如果你多方面努力最终没有联系到作者,由于
你编程能力不行,希望大神帮你实现这个数据的
预处理过程,那么希望你可以把数据源拿到,把
每个参数的意义,以及怎么处理的过程描述清楚,
再找大神帮你实现,因为这里大都是技术人员,
没有科研基础,你这个专业化的东西,我们搞不清楚,
除非你能把数据,过程,目标,这些都描述清楚,
我们对照着编码实现即可。
希望对您有所帮助!!!
稍微看了下,不准确则见谅
一、去白边
他3.2.1中说是对明显白边的区域直接裁剪,你可以用opencv将待处理图image的用阈值th阈值化成二值图,白边部分为非mask,中心内容为mask,以mask为掩膜生成新图img,为处理白边后的图像。
二、去除肌肉组织
他3.2.2里是用对特定列的像素值value,取为图像亮度阈值th_in,大于th_in的直接转为背景。你可以用opencv的threshold。
三、CLAHE
这个算法opencv有现成的函数,直接调用即可
四、形态学操作
为了让肿瘤部分更明显,所以他增加了腐蚀操作,opencv也有现成的函数erode
整个预处理函数如下,但我没图测试,你自己测
struct AdjustValues
{
size_t rowWhiteLines;
size_t colWhiteLines;
size_t histCountTh;
size_t imgGridSize;
size_t erodeSize;
uchar intensityth;
};
int preProcessFunc(Mat origin_img,AdjustValues onlinevalues,Mat &outputimg)
{
if(origin_img.empty() || origin_img.channels()!=1)
{
return -1;
}
int originrows=origin_img.rows;
int origincols=origin_img.cols;
size_t rowWhiteLines=onlinevalues.rowWhiteLines;
size_t colWhiteLines=onlinevalues.colWhiteLines;
uchar intensityth=onlinevalues.intensityth;
if(rowWhiteLines>originrows-3 || colWhiteLines>origincols-3)
{
return -2;
}
Mat validimg=origin_img(Rect(colWhiteLines,rowWhiteLines,origincols-colWhiteLines-1,originrows-rowWhiteLines-1));
Mat maskimg=Mat::zeros(validimg.size(),CV_8UC1);
cv::threshold(validimg,maskimg,intensityth,255,THRESH_BINARY);
Mat pureimg;
validimg.copyTo(pureimg,maskimg);
cv::Mat clahe_img;
cv::Ptr<cv::CLAHE> clahe = cv::createCLAHE();
clahe->setClipLimit(onlinevalues.histCountTh);
clahe->setTilesGridSize(Size(onlinevalues.imgGridSize,onlinevalues.imgGridSize));
clahe->apply(pureimg, clahe_img);
cv::Mat element = getStructuringElement(MORPH_RECT, Size(onlinevalues.erodeSize,onlinevalues.erodeSize));
cv::erode(clahe_img,outputimg,element);
return 0;
}
问题是强领域相关的,我仅从自己的理解和视觉方面的经验写了一段代码(一些地方调参),希望对你有所帮助
import cv2
import numpy as np
class Preprocessor:
def __init__(self, image):
self.image = image
def remove_white_border(self):
"""它将图像转换为灰度图像,然后对其进行阈值分割,以获得二值图像。接下来,它使用cv2.findContours函数查找图像中的轮廓,并使用cv2.boundingRect函数获取每个轮廓的边界框。最后,它将原始图像裁剪为只包含有用的内容,即仅保留轮廓的内容。"""
gray = cv2.cvtColor(self.image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 1, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
self.image = self.image[y:y+h, x:x+w]
return self.image
def remove_artifacts_and_pectoral_muscles(self):
"""首先,它将图像转换为灰度图像,然后对其进行阈值分割,以获得二值图像。接下来,它使用cv2.morphologyEx函数进行形态学操作,以关闭白色噪声。最后,它使用cv2.bitwise_and函数仅保留二值图像中的内容,以移除物品。"""
gray = cv2.cvtColor(self.image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV)
kernel = np.ones((5,5), np.uint8)
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
self.image = cv2.bitwise_and(self.image, self.image, mask=thresh)
return self.image
def apply_clahe(self):
"""该函数首先将图像转换为灰度图像,然后使用cv2.createCLAHE函数创建一个CLAHE对象。最后,它使用apply函数对灰度图像进行直方图均衡化。最后,它将图像再次转换为彩色图像。"""
gray = cv2.cvtColor(self.image, cv2.COLOR_BGR2GRAY)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
self.image = clahe.apply(gray)
self.image = cv2.cvtColor(self.image, cv2.COLOR_GRAY2BGR)
return self.image
def apply_morphological_operation(self):
"""该函数使用cv2.getStructuringElement函数创建一个椭圆形内核。然后使用cv2.morphologyEx函数执行形态学操作,在本例中为闭操作。这将合并图像中的缝隙和孔洞。"""
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
self.image = cv2.morphologyEx(self.image, cv2.MORPH_CLOSE, kernel)
return self.image
上面是预处理类的代码,下面一段是该类的使用方法:
# Load the original image
img = cv2.imread('path/to/image.jpg')
# Create an instance of the Preprocessor class
preprocessor = Preprocessor(img)
# Apply each preprocessing step on the image
img = preprocessor.remove_white_borders()
img = preprocessor.remove_artifacts_and_pectoral_muscles()
img = preprocessor.apply_clahe()
img = preprocessor.apply_morphological_operation()
# TODO:Use the processed image for YOLOv5 detection
- 这篇博客也许可以解决你的问题👉 :YOLOv5 报错怎么解决
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
非常非常感謝各位, 在此先結題了!!