怎样能把sparksql的查询结果导到本地和MySQL
问题遇到的现象和发生背景
遇到的现象和发生背景,请写出第一个错误信息
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
运行结果及详细报错内容
我的解答思路和尝试过的方法,不写自己思路的,回答率下降 60%
我想要达到的结果,如果你需要快速回答,请尝试 “付费悬赏”
我想把虚拟机的sparksql查询结果导到本地和MySQL
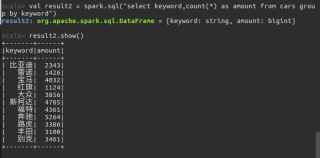
以下是我尝试但报错的语句

请问具体应该怎么做呢?如果把sparksql查询结果导到MySQL,那又该怎么做呢?
将 Spark SQL 查询结果导出到本地可以使用 DataFrame.write.format("csv").save("output") 方法,但是您遇到的错误是由于 Hadoop 集群连接问题导致的。可能是 Hadoop 集群没有正确启动或者端口 9000 被占用了。
将 Spark SQL 查询结果导出到 MySQL 中,可以使用 DataFrame.write.format("jdbc").options(Map("url" -> "jdbc:mysql://host:port/db", "dbtable" -> "table_name", "user" -> "username", "password" -> "password")).save() 方法。需要提前安装 MySQL 驱动并导入相应的依赖。
希望能对您有所帮助!回答有用请你采纳,点击回答右侧采纳即可!