python 做CSV 批量数据分析处理
Python 0基础,工作原因需要进行大量数据处理,问题如下:
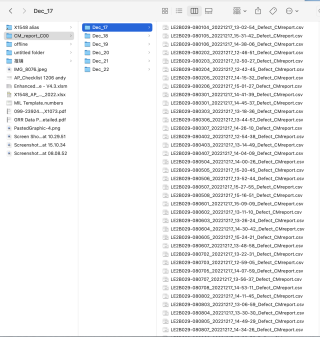
有以下路径:desktop/CM_report_C00/ 下多个sub folders, 每个sub- folder 有若干csv 文件,每个csv 文件内容如下图所示:
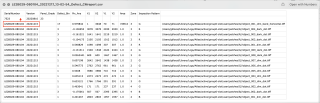
需要实现3个目标:
- 遍历所有子文件夹,统计csv 文件名中前14位出现的频次,例如 LE2B029-080104 出现1次,生成report.csv文件记录,此处并非遍历csv 内部内容的serial Number 出现的次数,只是看csv 文件名的前14位,确认是否有的产品测试了两次。
- 遍历所有csv 文件,将每个csv 的第三行前两列写入第二行前两列,无需生成新文件,在原文件做覆盖修改即可。
- 将第二步修改后的所有子文件夹的csv 文件merge 成一个allinone.csv,因原文件headname 最后一列缺失,增加最后一列的headname 为“path”
略附悬赏,望帮助
需注意的是,原文件的所有csv 文件,均如下图所示,最后一列没有head name,我之前尝试使用pandas 的时候会报错
引用ShowmeAI 的答案,报错如下:
##路径改成你的应该可以直接跑 ,试一下
import pandas as pd
import os
path='desktop/CM_report_C00/'
dirs=os.listdir(path) ##子文件夹
fct={}
allinone=pd.DataFrame()
for dir1 in dirs:
path1=path+dir1+'/'
fs=os.listdir(path1)
for f in fs:
fct[f[0:14]]=fct.get(f[0:14],0)+1 ##前14位的次数
df1=pd.read_csv(path1+f)
df1.iloc[0,0:2]=df1.iloc[1,0:2] ##第二行1,2列替换成第三行1,2列的值
df1.to_csv(path1+f,index=0) ##修改原始文件
allinone=pd.concat([allinone,df1]) ##合并修改后的结果
report=pd.DataFrame({'nm':fct.keys(),'ct':fct.values()})
report.to_csv('desktop/report.csv',index=0)
cols=list(df1.columns)
cols[-1]='path' ##最后一个head
allinone.columns=cols
allinone.to_csv('desktop/allinone.csv',index=0)
完整实现如下,望采纳,有问题再沟通。
import os
import csv
# 定义路径
path = "desktop/CM_report_C00/"
# 定义新的第一行
new_header = ["SerialNumber", "Version", "Panel_Grade", "Defect_Bin", "Pix_Ave", "X1", "X2", "Y1", "Y2", "Area", "Zone", "Inspection Pattern", "path"]
# 存储所有 csv 文件的路径
csv_paths = []
# 遍历所有子文件夹
for folder in os.listdir(path):
folder_path = os.path.join(path, folder)
# 遍历所有 CSV 文件
for file in os.listdir(folder_path):
if file.endswith(".csv"):
csv_path = os.path.join(folder_path, file)
csv_paths.append(csv_path)
# 遍历所有 CSV 文件
for csv_path in csv_paths:
with open(csv_path, "r") as file:
# 读取 CSV 文件
csv_reader = csv.reader(file)
# 获取第一行
header = next(csv_reader)
# 如果第一行不是预期的格式,则更新为新的格式
if header != new_header:
header = new_header
# 读取第二行
row1 = next(csv_reader)
# 读取第三行
row2 = next(csv_reader)
# 更新第二行的前两列
row1[0] = row2[0]
row1[1] = row2[1]
# 将修改后的 CSV 文件写回原文件
with open(csv_path, "w") as file:
# 写入修改后的第一行
csv_writer = csv.writer(file)
csv_writer.writerow(header)
# 写入修改后的第二行
csv_writer.writerow(row1)
# 写入剩余的行
csv_writer.writerows(csv_reader)
# 用于统计 SerialNumber 出现的频次的字典
serial_count = {}
# 遍历所有 CSV 文件
for csv_path in csv_paths:
with open(csv_path, "r") as file:
# 读取 CSV 文件
csv_reader = csv.reader(file)
# 跳过第一行
next(csv_reader)
# 遍历所有行
for row in csv_reader:
serial_number = row[0]
# 统计 SerialNumber 出现的频次
if serial_number in serial_count:
serial_count[serial_number] += 1
else:
serial_count[serial_number] = 1
# 将统计结果写入 report.csv 文件
with open("report.csv", "w") as file:
csv_writer = csv.writer(file)
# 写入表头
csv_writer.writerow(["SerialNumber", "Count"])
# 写入统计结果
for serial_number, count in serial_count.items():
csv_writer.writerow([serial_number, count])
# 把所有子文件夹的 csv 文件合并成一个 allinone.csv
with open("allinone.csv", "w") as file:
# 写入新的第一行
csv_writer = csv.writer(file)
csv_writer.writerow(new_header)
# 写入所有 CSV 文件的剩余行
for csv_path in csv_paths:
with open(csv_path, "r") as csv_file:
csv_reader = csv.reader(csv_file)
# 跳过第一行
next(csv_reader)
# 写入剩余的行
csv_writer.writerows(csv_reader)
用java可以不
可以试试,给采纳不
python 批量处理csv文件
可以借鉴下
https://blog.csdn.net/m0_46483236/article/details/125625074
1.可以使用 python 的 os 模块来遍历文件夹中的子文件夹,并使用 pandas 模块来统计 csv 文件中的数据。
import os
root_dir = '/path/to/root/dir'
for root, dirs, files in os.walk(root_dir):
for file in files:
# 在这里处理 csv 文件
对于每个 csv 文件,使用 pandas 读取文件中的数据,并统计前 14 位出现的频次。
import pandas as pd
if file.endswith('.csv'):
df = pd.read_csv(os.path.join(root, file))
counts = df['column_name'].str[:14].value_counts()
# 在这里处理 counts 数据
将 counts 数据汇总到一个数据框中,并使用 pandas 的 to_csv() 函数将数据写入 report.csv 文件中。
import pandas as pd
df_report = pd.DataFrame()
df_report = df_report.append(counts, ignore_index=True)
df_report.to_csv('report.csv', index=False)
2.使用 python 的 os 模块来遍历文件夹中的所有 csv 文件,然后使用 pandas 模块来读取文件中的数据,并完成所需的修改。
使用 os.walk() 函数遍历文件夹中的所有文件。
import os
root_dir = '/path/to/root/dir'
for root, dirs, files in os.walk(root_dir):
for file in files:
# 在这里处理 csv 文件
对于每个 csv 文件,使用 pandas 读取文件中的数据。
import pandas as pd
if file.endswith('.csv'):
df = pd.read_csv(os.path.join(root, file))
使用 iloc 属性和赋值运算符(=)来修改数据。
df.iloc[1, :2] = df.iloc[2, :2]
使用 pandas 的 to_csv() 函数将修改后的数据写回 csv 文件中。
df.to_csv(os.path.join(root, file), index=False)
3.使用 python 的 os 模块来遍历文件夹中的所有 csv 文件,然后使用 pandas 模块来读取文件中的数据,并将数据合并到一个数据框中。
使用 os.walk() 函数遍历文件夹中的所有文件。
import os
root_dir = '/path/to/root/dir'
for root, dirs, files in os.walk(root_dir):
for file in files:
# 在这里处理 csv 文件
对于每个 csv 文件,使用 pandas 读取文件中的数据。
import pandas as pd
if file.endswith('.csv'):
df = pd.read_csv(os.path.join(root, file))
在读取每个 csv 文件的数据后,使用 pandas 的 merge() 函数将数据合并到一个数据框中。
df_all = pd.merge(df_all, df, on='common_column')
在合并完所有 csv 文件后,使用 pandas 的 to_csv() 函数将合并后的数据写入 allinone.csv 文件中。
df_all.to_csv('allinone.csv', index=False)
dirname=r'C:\Users\Administrator\Desktop'
import os
import pandas as pd
def get_report_data(res_):
ress = res_.groupby(by = ['SerialNumber'])['SerialNumber'].count()
for idx in ress.index:
if len(idx) == 14:
report[idx] = report.get(idx, 0) + ress[idx]
def update_data(res_, filename_):
res_.iloc[0, :2] = res_.iloc[1, :2]
res_.to_csv(filename_, index = False)
def merge_data(df1,df2):
df1 = pd.concat([df1, df2])
return df1
folder = dirname + '/sub'
report = {}
for i, j, k in os.walk(folder):
if k:
df = pd.DataFrame(columns = range(1, 14))
for k1 in k:
if k1 == 'allinone.csv':continue
filename = os.path.join(i, k1)
res = pd.read_csv(filename)
get_report_data(res)#统计数量
update_data(res, filename)# 修改列
# 修改列名
colu = res.columns.tolist()
colu[-1] = 'path'
df.columns = colu
res.columns = df.columns
# 合并同一子目录数据
df = merge_data(df, res)
# 同一目录数据保存到文件
df = df.reset_index(drop = True)
df.to_csv(i + "/allinone.csv", index = False)
# 将所有csv的频次写入文件
with open(dirname + "/report.csv", 'w', newline = '', encoding = 'utf-8') as f:
print('code,count', file = f)
for k, v in report.items():
print(f"{k},{v}", file = f)
