python excel 批量替换
想实现如下功能:
读取如下表格,将代码一列进行文字替换,如第一行、第二行、第三行均替换为“张三”,第四行替换为“李四”。
注意:列表行数只是举例,实际会有N多行,如用replace一个个处理不现实吧,求好方法。(另外,需要替换的代码数字如需要也是可以单独提取出来的,比如有100行代码需要替换为张三,这100行代码数字都可以保存至excel中的)。
| 序号 | 代码 |
|---|---|
| 1 | 3425298909160 |
| 2 | 3425299502235 |
| 3 | 34253196711220 |
| 4 | 34252396904216 |
| 5 | 34252196803194 |
| 6 | 32342342352353 |
| 7 | 34253119650415 |
| 8 | 342531122314 |
| 9 | 3425312236515 |
| 还有很多行 | 还有很多行 |
| 序号 | 代码 |
|---|---|
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 李四 |
| 5 | 王五 |
| 6 | 王五 |
| 7 | 王五 |
| 8 | 王五 |
| 9 | 王五 |
| 还有很多行 | 还有很多行 |
以下截图更新,更好理解些
图1是需要被替换操作的表格
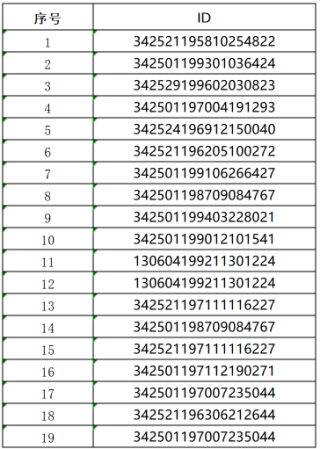
图2是对照表
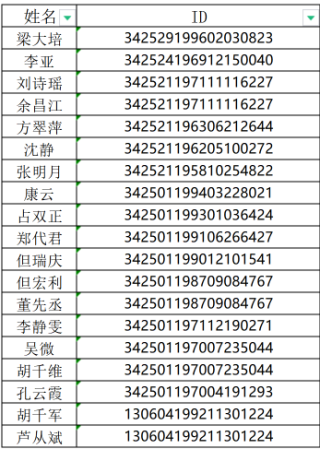
需要实现的是将 被替换操作表中的“ID”列的值,对应替换为对照表中的“姓名”列的值,数据很多,只是举例,一条条替换不现实的,有没有批量替换方法。
仔细看了看你的回答,提供了以下方案,可以将两个表拼在一起
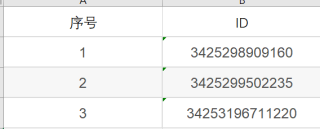
首先是新建两个excel,来模拟你的数据
number用来存放ID;
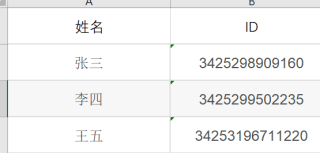
name用来存放姓名:
然后编写以下代码
import pandas as pd
path1 = r'C:\Users\ZLY\Desktop\number.xlsx' ##待替换的表
path2 = r'C:\Users\ZLY\Desktop\name.xlsx' ##姓名表
df1 = pd.read_excel(path1)
df2 = pd.read_excel(path2)
df3 = pd.merge(df2, df1, on='ID', how='outer')
df3.pop("序号")
print(df3)
输出结果为:

结果显示,该方法可以将 被替换操作表中的“ID”列的值,对应替换为对照表中的“姓名”列的值
如果能解决问题的话请点已采纳吧~~~~~
用openpyxl,添加一列数据,再将旧列删除
望采纳
需要使用 Python 的 openpyxl 库来读取和修改 Excel 文件。
- 首先,需要在终端或命令行中使用 pip 安装 openpyxl 库:
pip install openpyxl
- 然后,可以使用以下代码来读取 Excel 文件并将代码列中的值替换为新的值:
import openpyxl
# 读取 Excel 文件
wb = openpyxl.load_workbook('文件路径/文件名.xlsx')
# 选择工作表
ws = wb['Sheet1']
# 遍历每一行
for row in ws.rows:
# 获取代码列的值
code = row[1].value
# 如果代码值为 3425298909160、3425299502235 或 34253196711220,则将其替换为 "张三"
if code in [3425298909160, 3425299502235, 34253196711220]:
row[1].value = "张三"
# 如果代码值为 34252396904216,则将其替换为 "李四"
elif code == 34252396904216:
row[1].value = "李四"
# 如果代码值为 34252196803194、32342342352353、34253119650415、342531122314 或 3425312236515,则将其替换为 "王五"
elif code in [34252196803194, 32342342352353, 34253119650415, 342531122314, 3425312236515]:
row[1].value = "王五"
# 保存修改后的 Excel 文件
wb.save('文件路径/文件名.xlsx')
小哥,代号和姓名的对应关系是不是有另一张表,你一起发出来吧,不然楼上给你写的答案你可能也不会用
是将代码替换为代码对应的名字吗?
你题中的两个表关联一下就行了吧。就是vlookup 功能 其实也是两列关联
import pandas as pd
path1='F:/excel1.xlsx' ##代码的表
path1='F:/excel2.xlsx' ##待替换的表
df1=pd.read_excel(path1)
df2=pd.read_excel(path2)
df2.columns=['序号','代码名字']
df3=df1.merge(df2,on='序号',how='left')
print(df3)
是这个意思吗?
import pandas as pd
dict_replace = {(1, 3): '张三',
(4, 4): '李四',
(5, 8): '王五',
(9, ): '赵六',}
df = pd.read_excel("data.xlsx")
print(df)
for k, v in dict_replace.items():
if len(k) == 2:
df.iloc[k[0]-1:k[1], 1] = v
else:
df.iloc[k[0]-1:, 1] = v
print(df)
--result
序号 代码
0 1 234
1 2 3wer
2 3 2
3 4 23423
4 5 235w
5 6 y
6 7 ye
7 8 yeu
8 9 truut
序号 代码
0 1 张三
1 2 张三
2 3 张三
3 4 李四
4 5 王五
5 6 王五
6 7 王五
7 8 王五
8 9 赵六
2张表格的对应关系是什么? 就是说代码和名字的怎么去对应的? 有这个关系才能帮你写代码处理
用Python实现Excel表格的多对多批量替换
借鉴下
https://blog.csdn.net/YuXiaohUUUuu/article/details/126584361
使用 pandas 库中的 read_excel 函数来读取表格,并使用 loc 函数来选择需要替换的列
import pandas as pd
# 读取表格
df = pd.read_excel("table.xlsx")
# 选择需要替换的列
df.loc[:, "代码"] = "张三"
# 保存替换后的表格
df.to_excel("output.xlsx", index=False)
使用了 read_excel 函数读取了表格,然后使用 loc 函数选择了代码列,并将其替换为 "张三"。最后,我们使用 to_excel 函数将替换后的表格保存到新的 Excel 文件中。
如果你需要替换多行,可以使用一个循环来遍历行
import pandas as pd
# 读取表格
df = pd.read_excel("table.xlsx")
# 遍历行
for i in range(df.shape[0]):
# 如果是第一、二、三行,则将代码列替换为 "张三"
if i < 3:
df.loc[i, "代码"] = "张三"
# 否则,将代码列替换为 "李四"
else:
df.loc[i, "代码"] = "李四"
# 保存替换后的表格
df.to_excel("output.xlsx", index=False)