Python Pandas数据处理相关
求助,我正在做机器学习相关问题,现在我爬取得原始数据需要进行清洗,如下:
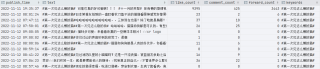
我希望能使用pandas库遍历每一行,然后将text中包含的keywords列字符串全部清理掉,请问我该怎么做,我目前做到的成果如下,似乎没有结果:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2022/12/4 1:22
# @Author : CherryWh1te
# @Site : www.mozac.tech
# @File : csv_tester.py
# @Software: PyCharm
import pandas as pd
df = pd.read_csv("./data/origin/2022-11-12_Hot_topic.csv")
df = df.dropna(axis=0,how='any')
for index,row in df.iterrows():
text = str(row['text']).replace(row['keywords'],"")
row['text'] = text.replace("#", "")
df.to_csv("./data/processed/cleaned_2022-11-12_Hot_topic.csv",index=False)
- 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:关于 Python 之 Pandas 的总结
直接用apply对dataframe处理吧,参考代码如下:
import pandas as pd
df = pd.read_csv("./data/origin/2022-11-12_Hot_topic.csv")
df = df.dropna(axis=0,how='any')
df['text'] = df.apply(lambda x: x['text'].replace(x['keywords'],""),axis=1)
df.to_csv("./data/processed/cleaned_2022-11-12_Hot_topic.csv",index=False)
另外,建议你print一下keywords列,确认一下它没有前后空格,有时候在csv文件里直接肉眼看看不出来,可能这也会导致替换失败。