如何在运行时,输入训练集目录下的所有文件?(语言-python)
问题遇到的现象和发生背景
https://github.com/codecat0/CV/tree/main/Image_Classification
参考的博客DenseNet网络结构详解及代码复现
在运行时只能输出训练集目录下的第一个类
运行结果及报错内容
这是我的结果:

第一个类只有197个对象:
我的解答思路和尝试过的方法
这是主程序:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model_name', type=str, default='densenet')
parser.add_argument('--num_classes', type=int, default=7)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch_size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.01)
parser.add_argument('--data_path', type=str, default=r'C:\Users\11831\Desktop\FinalProject\Code\data\training')
parser.add_argument('--flag', type=bool, default=False)
parser.add_argument('--device', default='cuda:0')
opt = parser.parse_args()
print(opt)
main(opt)
在data_utils.py中作者定义了read_split_data方法能够遍历文件夹,一个文件夹对应一个类别并且遍历每个文件夹下的文件。但实际效果不行。
def read_split_data(root: str, val_rate: float = 0.2, plot_image: bool = False):
# 保证随机结果可复现
random.seed(0)
assert os.path.exists(root), f'dataset root {root} does not exist.'
# 遍历文件夹,一个文件夹对应一个类别
flower_classes = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致
flower_classes.sort()
# 给类别进行编码,生成对应的数字索引
class_indices = dict((k, v) for v, k in enumerate(flower_classes))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as f:
f.write(json_str)
# 训练集所有图片的路径和对应索引信息
train_images_path, train_images_label = [], []
# 验证集所有图片的路径和对应索引信息
val_images_path, val_images_label = [], []
# 每个类别的样本总数
every_class_num = []
# 支持的图片格式
images_format = [".jpg", ".JPG", ".png", ".PNG"]
# 遍历每个文件夹下的文件
for cla in flower_classes:
cla_path = os.path.join(root, cla)
# 获取每个类别文件夹下所有图片的路径
images = [os.path.join(cla_path, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in images_format]
# 获取类别对应的索引
image_class = class_indices[cla]
# 获取此类别的样本数
every_class_num.append(len(images))
# 按比例随机采样验证集
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path:
val_images_path.append(img_path)
val_images_label.append(image_class)
else:
train_images_path.append(img_path)
train_images_label.append(image_class)
print(f"{sum(every_class_num)} images found in dataset.")
print(f"{len(train_images_path)} images for training.")
print(f"{len(val_images_path)} images for validation.")
if plot_image:
plt.bar(range(len(flower_classes)), every_class_num, align='center')
plt.xticks(range(len(flower_classes)), flower_classes)
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
plt.xlabel('image class')
plt.ylabel('number of images')
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
我想要达到的结果
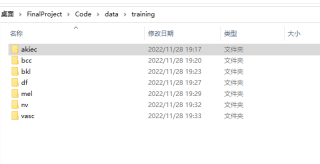
程序能够遍历training文件夹下的七个文件,并读取其中的全部图片。
不能遍历所有的目录, 原因就在于 return 的位置在for循环之内, 放到外面就可以遍历training了, 代码改动如下
def read_split_data(root: str, val_rate: float = 0.2, plot_image: bool = False):
# 保证随机结果可复现
random.seed(0)
assert os.path.exists(root), f'dataset root {root} does not exist.'
# 遍历文件夹,一个文件夹对应一个类别
flower_classes = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致
flower_classes.sort()
# 给类别进行编码,生成对应的数字索引
class_indices = dict((k, v) for v, k in enumerate(flower_classes))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as f:
f.write(json_str)
# 训练集所有图片的路径和对应索引信息
train_images_path, train_images_label = [], []
# 验证集所有图片的路径和对应索引信息
val_images_path, val_images_label = [], []
# 每个类别的样本总数
every_class_num = []
# 支持的图片格式
images_format = [".jpg", ".JPG", ".png", ".PNG"]
# 遍历每个文件夹下的文件
for cla in flower_classes:
cla_path = os.path.join(root, cla)
# 获取每个类别文件夹下所有图片的路径
images = [os.path.join(cla_path, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in images_format]
# 获取类别对应的索引
image_class = class_indices[cla]
# 获取此类别的样本数
every_class_num.append(len(images))
# 按比例随机采样验证集
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path:
val_images_path.append(img_path)
val_images_label.append(image_class)
else:
train_images_path.append(img_path)
train_images_label.append(image_class)
print(f"{sum(every_class_num)} images found in dataset.")
print(f"{len(train_images_path)} images for training.")
print(f"{len(val_images_path)} images for validation.")
if plot_image:
plt.bar(range(len(flower_classes)), every_class_num, align='center')
plt.xticks(range(len(flower_classes)), flower_classes)
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
plt.xlabel('image class')
plt.ylabel('number of images')
plt.title('flower class distribution')
plt.show()
# 改动
return train_images_path, train_images_label, val_images_path, val_images_label
我看了一下代码,他这代码写的应该没什么问题啊,可以遍历到这7个文件夹,并读取文件的。
如果只是读了一个类里面的图片,那应该是你的目录结构(root)给错了,把当前的root的上一层传进去看看结果