关于#pandas#的问题,如何解决?(语言-python)
目前已知一个购物清单,原题目如下
交易数据集;每行数据代表一个用户购物的交易记录;共计1万条记录。1代表对应物品被购买,0代表没有购买。
请使用pandas将数据导入为dataframe,物品名作为列名。
请统计各个物品被购买的情况,给出对应各个物品被购买的基本统计数据,并进行对比。对所有物品进行统计分析,包括min/max/Q1/Q3 和中位数,并绘制盒图等多个统计图进行对比。
此外,请统计超市中每笔交易购买物品的情况,使用相似的分析思路进行对比。
删除购置物品最少的2000笔交易记录,将剩余的数据导出为csv格式。与对应的notebook文件压缩后一同上传。
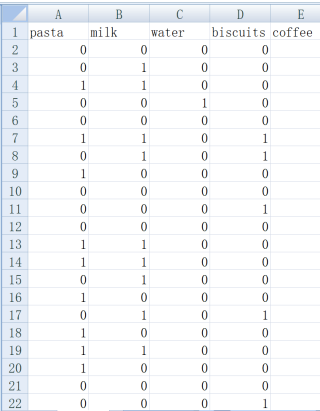
请问应当如何用pandas和numpy统计每一列数据之后再进行绘图,并且如何删除最少的2000笔交易记录
###按着你的题目写的简易的
import pandas as pd
import matplotlib.pyplot as plt
path1='D:/ZZF/data.xlsx' ##你的文件路径
df1=pd.read_excel(path1) ##读入数据,以第一行商品维列名
print(df1.describe()) ##打印出每个商品的最大最小,分位数,中位数等
fig = plt.figure()
plt.boxplot(df1) ##盒图
plt.show()
df1['sum']=df1.sum(axis=1) ##统计每笔交易的购买数量
fig = plt.figure()
plt.hist(df1) ##柱状图
plt.show()
df2=df1.sort_values(by='sm',ascending=0) ##按数量排序
df3=df2.head(len(df2)-2000) ##剔除后两千条
df3.to_excel('data2.xlsx',index=0) ##导出数据
将单列数据取出,然后进行判断统计呗

import pandas as pd
df = pd.DataFrame([[1,0,1,1],
[0,1,1,1],
[0,0,1,1]])
# df = pd.read_csv('csv路径')
# 可直接查看每列数据情况
print(df.describe())
按列遍历,统计min/max/Q1/Q3 和中位数,再用Matplotlib绘图。再按行遍历,统计每条交易购买的物品数,从小到大排序,删除2000个即可
- 这篇文章讲的很详细,请看:使用 pandas 遇到的报错
- 你还可以看下python参考手册中的 python-Python 语言服务
np.sum(data["商品名"]=1)就可以统计每个商品被购买了几次。
Q1、Q3中位数等等,你可以用matplotlib或者seaborn绘制一个箱线图,就可以得到这些值。
请参考 一切因为有你
这么简单的东西你就是想白嫖作业把