scrapy下载图片后只能保存最后一个item的文本信息
scrapy下载图片后只能保存最后一个item的文本信息
spider部分
import scrapy
from myscrapy.items import musicItem
class doubanAlbumSpider(scrapy.Spider):
name = "albumspider"
start_urls = ['https://music.douban.com/tag/%E6%91%87%E6%BB%9A?start=0&type=T']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://music.douban.com/tag/%E6%91%87%E6%BB%9A?start=0&type=T'
yield scrapy.Request(url, headers=self.headers)
def parse(self,response):
item = musicItem()
albums = response.xpath(r"//tr[@class='item']")
for album in albums:
item['alname'] = " ".join(album.xpath(r"./td/div/a/text()")[0].extract().split())
item['detailUrl'] = album.xpath(r"./td/a/@href")[0].extract()
item['imageUrl'] = (r"/m/").join(album.xpath(r"./td/a/img/@src")[0].extract().split(r"/s/"))
yield(item)
item部分
class musicItem(scrapy.Item):
alname = scrapy.Field()
imageUrl = scrapy.Field()
detailUrl = scrapy.Field()
image = scrapy.Field()
image_paths = scrapy.Field()
加入的pipeline
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class DoubanImagePipeline(ImagesPipeline):
default_headers = {
'accept': 'image/webp,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, sdch, br',
'accept-language': 'zh-CN,zh;q=0.8,en;q=0.6',
'cookie': 'bid=yQdC/AzTaCw',
'referer': 'https://www.douban.com/',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
}
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['imageUrl'])
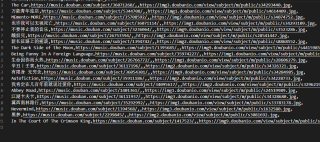
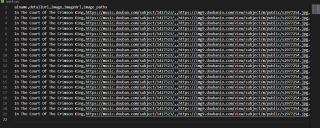
在没有添加存储的pipeline时,所有数据都能保存(专辑名,封面url和详情页url),但加入pipeline后虽然图片可以正常下载,但是前面保存的数据都被最后一行覆盖了。