字符串多行每一行,怎么减去1个空格?
# 方法一 切片
def aiphabet_graphics(n,m):
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for i in range(n):
res_1 = letter[1:i+1]
res_2 = letter[0:m+1]
res = res_1[::-1] + res_2
print(res[0:m])
pass
pass
n,m = map(int,input().split())
aiphabet_graphics(n,m)
# 方法二 循环
n,m = map(int,input().split())
if(n>=1 and m<=26):
for i in range(n):
k,t1,t2=i,0,1
for j in range(m):
if (k<=i and k>=0):
print(chr(65+i-t1),end='')
t1,k=t1+1,k-1
else:
print(chr(65+t2),end='')
t2=t2+1
print("")
# 这段代码是蓝桥杯题型,当我运行的时候,发现有的前面有个空格
我cv您的代码试炼了,代码每行前有一个空格,这是不符python “代码规范”,运行必报错。我手动去除后运行了代码,可以正常输出,但可以稍作“优化”。也可以代码去除“行首空格”,示例在后。
您的代码
# 方法一 切片
def aiphabet_graphics(n,m):
''' 逐个反转字符 '''
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for i in range(n):
res_1 = letter[1:i+1] # 截取第二个字符到第i个字符。
res_2 = letter[:m+1] # 截取m个字符。切片从头起可以省略,python切片默认从头开始。
res = res_1[::-1] + res_2 #
print(res[:m]) # 打印组合字符串前m个字符。
pass
pass
n, m = map(int,input('\n输入两个整数(如4 7):').split())
aiphabet_graphics(n, m)
# 方法二 循环
n, m = map(int,input('\n输入两个整数(如4 7):').split())
#if n in (c := range(1, 27)) and m in c:
if 1 < n < 26 and 0 <= m <26:
for i in range(n):
k,t1,t2=i,0,1
for j in range(m):
if (k<=i and k>=0):
print(chr(65+i-t1),end='')
t1,k=t1+1,k-1
else:
print(chr(65+t2),end='')
t2=t2+1
print("")
else:
print(f"\n{' 输入错误!':~^45}")
# 这段代码是蓝桥杯题型,当我运行的时候,发现有的前面有个空格
输出及循环报错截屏图片
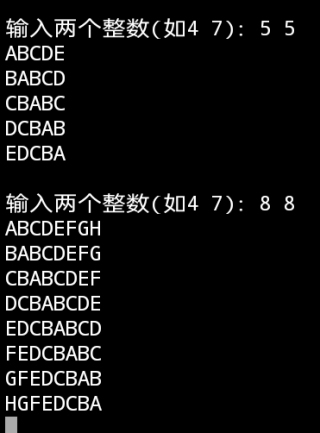

行首空格去除
方法一 切片
按行读取后string[1:]切片,第二个字符起。可用解析可用循环。
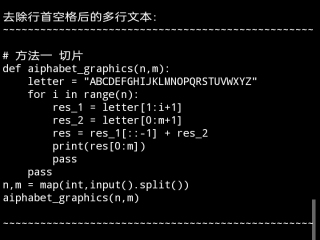
我用解析式对你的第一段代码进行了试炼。思路解析:用string.split()方法以回车换行“\n“符拆分字符串为以行为单位的列表,再用map()函数以匿名函数lambda对列表元素进行切片操作去除行首空格,最后用string.join()方法以“\n”回车换行符粘接去除空格后的多行字符列表元素,还原多行字符。
#!/usr/bin/nve python
# coding: utf-8
text = '''
# 方法一 切片
def aiphabet_graphics(n,m):
letter = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for i in range(n):
res_1 = letter[1:i+1]
res_2 = letter[0:m+1]
res = res_1[::-1] + res_2
print(res[0:m])
pass
pass
n,m = map(int,input().split())
aiphabet_graphics(n,m)
'''
text = '\n'.join(map(lambda x: x[1:], text.split('\n')))
print(f"\n去除行首空格后的多行文本:\n{'~'*50}\n{text}\n{'~'*50}\n")
效果截屏图片
方法二 用字符串方法lstrip()去除左侧所有空格、strip()去除前后空格。对前例的代码多行字符不适用。
text = '\n'.join(map(lambda x: x.lstrip(), text.split('\n')))
text = '\n'.join(map(lambda x: x.strip(), text.split('\n')))
方法三 字符串拆分方法split()。依然不适用代码字符串。
text = '\n'.join(map(lambda x: ''.join(x.split(' ')), text.split('\n')))
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7529622
+如果每行字符串有且只有一个空格去除:
-如果空格在行首:
str.lstrip(' ')
-如果空格在行尾:
str.rstrip(' ')
-如果空格在行首或行尾:
str.strip(' ')
-如果空格在每行字符串中的任意位置:
str.replace(' ', '')
-如果空格在每行字符串中的相同位置:
str = str[:str.find(' ')] + str[str.find(' ')+1:]
+如果每行字符串有多个空格去除:
-如果空格在行首或行尾:
str.strip(' ')
-如果空格在每行字符串中的任意位置:
str.replace(' ', '')