python生成的exe文件闪退,显示no module named 'charset_normalizer.md__mypyc'
python生成了exe文件,在pycharm中可以正常执行,但执行exe文件时闪退
import PyPDF2
import pdfplumber
def extract_content(pdf_path):
# 内容提取,使用 pdfplumber 打开 PDF,用于提取文本
with pdfplumber.open(pdf_path) as pdf_file:
# 使用 PyPDF2 打开 PDF 用于提取图片
pdf_image_reader = PyPDF2.PdfFileReader(open(pdf_path, "rb"))
print(pdf_image_reader.getNumPages())
content = ''
# len(pdf.pages)为PDF文档页数,一页页解析
for i in range(len(pdf_file.pages)):
# pdf.pages[i] 是读取PDF文档第i+1页
page_text = pdf_file.pages[i]
# page.extract_text()函数即读取文本内容
page_content = page_text.extract_text()
if page_content:
content = content + page_content
print(page_content)
a = input('请输入需要提取的PDF路径及文件名:')
extract_content(a)
运行exe文件时闪退,我录视频截图发现问题:
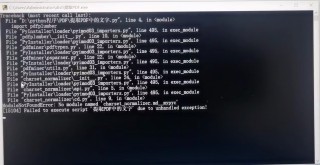
找了很多同类型的问题,但实际操作还是没有解决。
请问怎么样能让exe文件正常运行?
把所有库和依赖都添加到PYHONPATH里,或者全局安装依赖库