Python数据可视化笨蛋问题
有没有会数据可视化分析的专业人员,搭理我一些笨蛋问题,因为他们给我代码,我可能也不会,因为我就没有学过,我需要你们看着我的代码,然后来给我解决问题
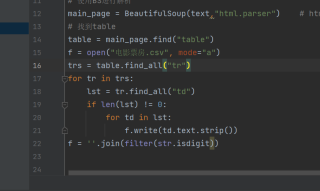
问题是啥?
你的爬虫不是写的挺好的嘛。。。。
What are you doingᥬ😂᭄
举个小例子,对比着看看,不知道有没有帮助
import bs4
xml_str = \
'''
<?xml version="1.0" encoding="windows-1251"?>
<root category1="0000" category2="1111">
<subject d1="S">
<name a1="A0">aaaa</name>
<code c1="9999">010010</code>
<brithdata>20080101</brithdata>
<height>170</height>
<weight>55kg</weight>
<activities/>
</subject>
<subject d1="S">
<name a1="A0">aaaa</name>
<code c1="9999">000002</code>
<brithdata>20080101</brithdata>
<height>168</height>
<weight>50kg</weight>
<activities/>
</subject>
</root>
'''
soup1 = bs4.BeautifulSoup(xml_str, 'lxml')
# find( name , attrs , recursive , text , **kwargs )
codes = soup1.find(name='code', attrs={'c1': '9999'}) # 取第一个
print('标签:', codes.name)
print('属性:', codes.attrs)
print('内容:', codes.text)
# find_all( name , attrs , recursive , text , **kwargs )
codes = soup1.findAll(name='code', attrs={'c1': '9999'}) # 取所有的
code_all = []
for i in codes:
code_all.append(i.text)
print('code_all:', code_all)
# 标签: code
# 属性: {'c1': '9999'}
# 内容: 010010
# code_all: ['010010', '000002']
csv 建议使用pandas
建议使用pandas