pandas读取execl后的数据如何引用第一列为列表
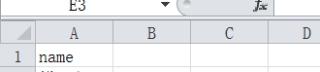
两个Excel表格,名称分别为“报表”、“NC”均为1张sheet,数据均在第1张sheet中第一列,已利用pandas读取数据,想利用第一列创建列表,且第一行第一列名称已经改为name,系统依然报错,请问大家需要如何解决。或者需要如何调整代码,才能将第一列成功构建列表
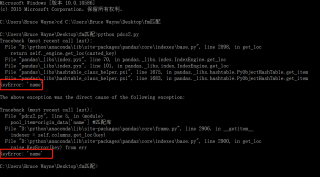
删除index_col参数即可,你对这个参数理解有误
useclos参数表示你需要读取哪些列,index_col表示用这作为行索引,所以name列当索引列了
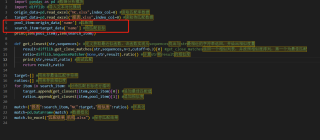
import pandas as pd
import difflib
origin_data=pd.read_excel("NC.xlsx")
target_data=pd.read_excel("report.xlsx")
pool_item=origin_data['name']
search_item=target_data['name']
print(len(pool_item),len(search_item))
def get_closest(str,sequences):
result=difflib.get_close_matches(str,sequences,n=1,cutoff=0.3)
result=result if result else []
ratio=difflib.SequenceMatcher(None,str,result).ratio()
return result,ratio
search_keys=[]
target=[]
ratios=[]
for item in search_item:
result,ratio = get_closest(item,pool_item)
if (len(result)==0):
continue
search_keys.append(item)
target.append(result)
ratios.append(ratio)
match={"tr12":search_keys,"NC":target,"t3":ratios}
match=pd.DataFrame(match)
print(match)
match.to_excel("test.xlsx")
把你的index_col=0删除了
