求写spark SQL语句 去重 选取时间
同一个人日期有重复的去要去重 并且对照系统时间选取半年以内的数据 必须保留所有字段
平台是MPP框架下的Vertica数据库 这个表有几万条的数据 要求写sparkSQL
我的表名$t2
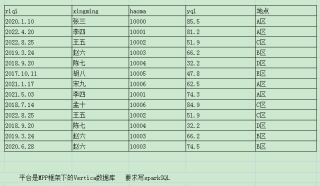

根据姓名、日期进行分组可以达到去重效果。
select * from 表名 group by xingming,riqi
with t1 as (
select '20200110' riqi ,'张三' name1, 10000 haoma ,85.5 yql ,'A区' didian union ALL
select '20220420' riqi ,'李四' name1, 10001 haoma ,81.2 yql ,'A区' didian union ALL
select '20220825' riqi ,'王五' name1, 10002 haoma ,51.9 yql ,'C区' didian union ALL
select '20190224' riqi ,'赵六' name1, 10003 haoma ,66.2 yql ,'B区' didian union ALL
select '20180920' riqi ,'陈七' name1, 10004 haoma ,32.2 yql ,'D区' didian union ALL
select '20171011' riqi ,'胡八' name1, 10005 haoma ,47.8 yql ,'E区' didian union ALL
select '20210117' riqi ,'宋九' name1, 10006 haoma ,62.5 yql ,'A区' didian union ALL
select '20220503' riqi ,'李四' name1, 10001 haoma ,74.3 yql ,'A区' didian union ALL
select '20220714' riqi ,'孟十' name1, 10006 haoma ,84.9 yql ,'C区' didian union ALL
select '20220825' riqi ,'王五' name1, 10002 haoma ,51.9 yql ,'C区' didian union ALL
select '20180920' riqi ,'陈七' name1, 10004 haoma ,32.2 yql ,'D区' didian union ALL
select '20190324' riqi ,'赵六' name1, 10003 haoma ,66.2 yql ,'B区' didian union ALL
select '20190628' riqi ,'赵六' name1, 10003 haoma ,74.5 yql ,'B区' didian
)
select * from (
select ROW_NUMBER()OVER(PARTITION BY riqi,name1 ORDER BY riqi) RO ,riqi,name1,haoma,yql,didian
from t1
WHERE TO_TIMESTAMP(RIQI,'yyyyMMdd') <= NOW()
and TO_TIMESTAMP(RIQI,'yyyyMMdd') >= date_add(NOW() ,-180)
ORDER BY RIQI,NAME1 )
where ro = 1 ;
select b.riqi,b.xingming,b.haomao,b.yql,b.`地点`
from
(select row_number()over(partition by xingming order by riqi desc) rn,
a.*
from
(select * from $t2 where to_date(riqi) > add_months(current_date, -6))a
)b
where rn=1
在黑窗口中操作 spark.sql(select * from $t2
where riqi>=date_format(date_sub(now(),interval 6 month),'%y.%m.%d')
group by xingming,riqi)
如果用Java写 加上
val spark: SparkSession = SparkSession.builder()
.appName("test")
.master("local[*]")
.config("hive.metastore.uris" ,"thrift://192.168.153.135:9083")
.enableHiveSupport()
.getOrCreate()
import org.apache.spark.sql._
import org.apache.spark.sql.types._
import scala.util._
import spark.implicits._
spark.sql(select * from $t2
where riqi>=date_format(date_sub(now(),interval 6 month),'%y.%m.%d')
group by xingming,riqi)
一个rank by having =1 的问题。