python爬取房源,可以运行,但是每次只爬出一条是什么原因?
from lxml import etree
import requests
import csv
import time
def spider():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'
}
pre_url = 'https://hefei.qfang.com/rent/f'
for x in range(1, 13):
html = requests.get(pre_url + str(x), headers=headers)
time.sleep(2) # 在每一次GET后,等待2秒
selector = etree.HTML(html.text)
# 先获取房源列表
house_list = selector.xpath("//*[@id='cycleListings']/ul/li")
for house in house_list:
xiaoqu = house.xpath("div[2]/div[3]/div/a/text()")[0]
huxing = house.xpath("div[2]/div[2]/p[1]/text()")[0]
area = house.xpath("div[2]/div[2]/p[2]/text()")[0]
month_price = house.xpath("div[3]/p/span[1]/text()")[0]
item = [xiaoqu, huxing, area, month_price]
data_writer(item)
print('正在抓取', xiaoqu)
def data_writer(item):
with open('qfang_chuzufang.csv','a+',encoding='utf-8',newline='')as csvfile:
writer = csv.writer(csvfile)
writer.writerow(item)
if __name__ == '__main__':
spider()
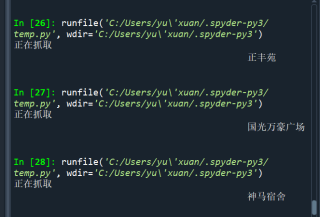
已修改,爬到不止一页,就是你信息提取包括了一些其他符号,自己再处理一下就好了
from lxml import etree
import requests
import csv
import time
def spider():
print("stater")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'
}
pre_url = 'https://hefei.qfang.com/rent/f'
for x in range(1, 13):
html = requests.get(pre_url + str(x), headers=headers)
time.sleep(2) # 在每一次GET后,等待2秒
selector = etree.HTML(html.text)
# 先获取房源列表
house_list = selector.xpath("//*[@id='cycleListings']/ul/li")
for house in house_list:
xiaoqu = house.xpath("div[2]/div[3]/div/a/text()")[0]
huxing = house.xpath("div[2]/div[2]/p[1]/text()")[0]
area = house.xpath("div[2]/div[2]/p[2]/text()")[0]
month_price = house.xpath("div[3]/p/span[1]/text()")[0]
item = [xiaoqu, huxing, area, month_price]
print(item)
# data_writer(item)
print('正在抓取', xiaoqu)
# def data_writer(item):
# with open('qfang_chuzufang.csv', 'a+', encoding='utf-8', newline='') as csvfile:
# writer = csv.writer(csvfile)
# writer.writerow(item)
if __name__ == '__main__':
spider()
这三行往右缩进就行了
item = [xiaoqu, huxing, area, month_price]
data_writer(item)
print('正在抓取', xiaoqu
你这只爬了一页内容,你要分析那个负责页码的那个参数例如page之类的,然后仿造这个参数,不断for循环请求每一页呀。
翻页爬取一个 for 循环不就行,它的 URL ,前面的路径都是一样的,只不过是有一个参数在控制页码,例如 page 之类的,你每次只不过需要构造这个参数,用 range 生成就行, for i in range (1,51),像这样是不是已经构造出了一道50?,这就是一到五十页呀,你把构造出来的这个i加到循环里面加到
那个 url 里的 page 参数后不就行了,然后 request 不就好了。